
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 400 420 440 460 | |
| | | | | | | | | | | | | | | | | | | | | | | | | |
| MASPALAAALAVAAAAGPNASGAGERGSGGVANASGASWGPPRGQYSAGAVAGLAAVVGFLIVFTVVGNVLVVIAVLTSRALRAPQNLFLVSLASADILVATLVMPFSLANELMAYWYFGQVWCGVYLALDVLFCTSSIVHLCAISLDRYWSVTQAVEYNLKRTPRRVKATIVAVWLISAVISFPPLVSLYRQPDGAAYPQCGLNDETWYILSSCIGSFFAPCLIMGLVYARIYRVAKLRTRTLSEKRAPVGPDGASPTTENGLGAAAGAGENGHCAPPPADVEPDESSAAAERRRRRGALRRGGRRRAGAEGGAGGADGQGAGPGAAESGALTASRSPGPGGRLSRASSRSVEFFLSRRRRARSSVCRRKVAQAREKRFTFVLAVVMGVFVLCWFPFFFSYSLYGICREACQVPGPLFKFFFWIGYCNSSLNPVIYTVFNQDFRRSFKHILFRRRRRGFRQ | |
| CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCSSSCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCSSSSSCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCHHHCCCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHCCHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHCCHHHHHHHHHHHCCCCCCCCCC | |
| 989988766432247888888877788888788877677898667778899999999999999999978871664561366675469999999999999999973199999984715387489999999999999999999999987536632634017553368999999999999999999999981754348876870165217578877988979999999999999999999998888751234522223334543100013567766665543222344433333445432223344334553221223333344333333234555544444432223333300111011124544434102346788888788876678789888503699999999980752455259999999999988312489999828999999999964555564679 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 400 420 440 460 | |
| | | | | | | | | | | | | | | | | | | | | | | | | |
| MASPALAAALAVAAAAGPNASGAGERGSGGVANASGASWGPPRGQYSAGAVAGLAAVVGFLIVFTVVGNVLVVIAVLTSRALRAPQNLFLVSLASADILVATLVMPFSLANELMAYWYFGQVWCGVYLALDVLFCTSSIVHLCAISLDRYWSVTQAVEYNLKRTPRRVKATIVAVWLISAVISFPPLVSLYRQPDGAAYPQCGLNDETWYILSSCIGSFFAPCLIMGLVYARIYRVAKLRTRTLSEKRAPVGPDGASPTTENGLGAAAGAGENGHCAPPPADVEPDESSAAAERRRRRGALRRGGRRRAGAEGGAGGADGQGAGPGAAESGALTASRSPGPGGRLSRASSRSVEFFLSRRRRARSSVCRRKVAQAREKRFTFVLAVVMGVFVLCWFPFFFSYSLYGICREACQVPGPLFKFFFWIGYCNSSLNPVIYTVFNQDFRRSFKHILFRRRRRGFRQ | |
| 744443423232233333122233343433333334333433334221000001002002102201310200000002123012000000000010000000000110000001120210300000000000000000010000000000100020030333113100000000000100100100000022246644332020223200000001100310000002002200100131043145344434344443343443443333444422333233344443443454444341343223331213222222224324343223221222222222221222122222223243444434333332332442300000000000122002101211001000331030120000000010020000000000000430130012000122344348 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 400 420 440 460 | | | | | | | | | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCSSSCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCSSSSSCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCHHHCCCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHCCHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHCCHHHHHHHHHHHCCCCCCCCCC MASPALAAALAVAAAAGPNASGAGERGSGGVANASGASWGPPRGQYSAGAVAGLAAVVGFLIVFTVVGNVLVVIAVLTSRALRAPQNLFLVSLASADILVATLVMPFSLANELMAYWYFGQVWCGVYLALDVLFCTSSIVHLCAISLDRYWSVTQAVEYNLKRTPRRVKATIVAVWLISAVISFPPLVSLYRQPDGAAYPQCGLNDETWYILSSCIGSFFAPCLIMGLVYARIYRVAKLRTRTLSEKRAPVGPDGASPTTENGLGAAAGAGENGHCAPPPADVEPDESSAAAERRRRRGALRRGGRRRAGAEGGAGGADGQGAGPGAAESGALTASRSPGPGGRLSRASSRSVEFFLSRRRRARSSVCRRKVAQAREKRFTFVLAVVMGVFVLCWFPFFFSYSLYGICREACQVPGPLFKFFFWIGYCNSSLNPVIYTVFNQDFRRSFKHILFRRRRRGFRQ | |||||||||||||||||||||||||
| 1 | 4iaqA | 0.29 | 0.28 | 0.79 | 2.48 | Download | ---------------------------------------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFFWR------QASECVVNTDHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIADLEDNWETLNDNLKVI------------------------------------NAAQVKDALTKMRAAALDAQKATPDSPEMKDFRHGFDILVGQIDDALKLANEGKVKEAQAAAEQLKTTRNAYIQKYLLMAARERKATKTLGIILGAFIVCWLPFFIISLVMP-------IHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK------- | |||||||||||||||||||
| 2 | 4ib4A | 0.26 | 0.26 | 0.79 | 4.48 | Download | --------------------------------------------------LHWAALLILMVIIPTIGGNTLVILAVSLEKKLQYATNYFLMSLAVADLLVGLFVMPIALLTIMFAMWPLPLVLCPAWLFLDVLFSTASIWHLCAISVDRYIAIKKPIQANQYNSRATAFIKITVVWLISIGIAIPVPIKGIETNPNNITCVLTKERFGDFMLFGSLAAFFTPLAIMIVTYFLTIHALQKKAADLEDNWETLNDNLKVIEKADNAAQ----------------------------------------VKDALTKMRAAALDAQKKDFRHGFDILVGQIDDALKLANEGKVKEAQAAAEQLKTTRNAYIQKYLQTISNEQRASKVLGIVFFLFLLMWCPFFITNITLVLCDSCQTTLQMLLEIFVWIGYVSSGVNPLVYTLFNKTFRDAFGRYITCNYR----- | |||||||||||||||||||
| 3 | 5wiuA | 0.30 | 0.30 | 0.81 | 3.08 | Download | --------------------------------------------------GAAALVGGVLLIGAVLAGNSLVCVSVATERALQTPTNSFIVSLAAADLLLALLVLPLFVYSEVQGAWLLSPRLCDALMAMDVMLCTASIFNLCAISVDRFVAVAVPLRYNRQGGSRRQLLLIGATWLLSAAVAAPVLCGLND-------PAVCRLEDRDYVVYSSVCSFFLPCPLMLLLYWATFRGLQRWEV-------------------ARRADLEDNWETLNDNLKVIEKADNAAQVKDALTKMRAAALDAQKATPPKLEDKSPPEMKDFRHGFDILVGQIDDALKLANEGKVKEAQAAAEQLKTTRNAYI--QKYLAKITGRERKAMRVLPVVVGAFLLCWTPFFVVHITQALCPA-CSVPPRLVSAVTWLGYVNSALNPVIYTVFNAEFRNVFRKA----------- | |||||||||||||||||||
| 4 | 4ib4 | 0.28 | 0.26 | 0.80 | 1.57 | Download | -----------------------------------------EEQ---GNKLHWAALLILMVIIPTIGGNTLVILAVSLEKKLQYATNYFLMSLAVADLLVGLFVMPIALLTIMFAMWPLPLVLCPAWLFLDVLFSTASIWHLCAISVDRYIAIKKPIQANQYNSRATAFIKITVVWLISIGIAIPVIKGIETN---PNNITCVLTKERDFMLFGSLAAFFTPLAIMIVTYFLTIHALQKKAADLEDNWETLNDNLK--VIEKADNA-AQV-KDAL-----TKMRAAALD----A--QKKDFRHGFD----ILV------GQ----IDDALK-LANEGKVKE------A-QAAAEQ--L-KTTRNAYIQKYLQTISNEQRASKVLGIVFFLFLLMWCPFFITNITLVLCDSCNTTLQMLLEIFVWIGYVSSGVNPLVYTLFNKTFRDAFGRYITCNYR----- | |||||||||||||||||||
| 5 | 3uon | 0.22 | 0.24 | 0.87 | 1.24 | Download | -----------------------------------------------TFEVVFIVLVAGSLSLVTIIGNILVMVSIKVNRHLQTVNNYFLFSLACADLIIGVFSMNLYTLYTVIGYWPLGPVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPVKRTTKMAGMMIAAAWVLSFILWAPAILFWQFIVGVVEDGECYIQSNAAVTFGTAIAAFYLPVIIMTVLYWHISRASKSRINIFEMLRIDEGLRLKIYKDTEGYTIGHLLTKSPSLAAKLDKAIGRNTNGVITKDEKLFRGILRNAKKPVYDSLDAVRRALINVFQMGETGAGRMLQQKRWDEAAVNLAKSTPNRAKRVITTFRTGTWDAYPPPSREKKVTRTILAILLAFIITWAPYNVMVLINTFCAPC--IPNTVWTIGYWLCYINSTINPACYALCNATFKKTFKHLLM--------- | |||||||||||||||||||
| 6 | 5tgzA | 0.17 | 0.24 | 0.90 | 3.40 | Download | -------------------------------GRGENFMDIECFMVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRK-DSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLGWNCEKL---QSVCSDIFPHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAVAKALADAGYEVDSRDAASVEAGGLFEGFDLVLLGCSTWGDDSIELQDDFIPLFDSLEETGAQGRKVACFGCGDSSWEYFCGAVDAIEEKLKNLGAEIVQDGLRIDGDPRAARDDIVGWAHDVRGAIPDQARMDIELAKTLVLILVVLIICWGPLLAIMVYDVFG-KMNKLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF---------- | |||||||||||||||||||
| 7 | 4ib4 | 0.28 | 0.26 | 0.79 | 1.75 | Download | ----------------------------------------------------WAALLILMVIIPTIGGNTLVILAVSLEKKLQYATNYFLMSLAVADLLVGLFVMPIALLTIMEAMWPLPLVLCPAWLFLDVLFSTASIWHLCAISVDRYIAIKKPIQANQYNSRATAFIKITVVWLISIGIAIPPIKGIETN-PNNITCVLTKERFGDFMLFGSLAAFFTPLAIMIVTYFLTIHALQKKAADLEDNWETLNDNLKVIEKADN-AAQVK-------------------DALTKMRAAALDAQKKDFRHGFDILV-GQID--------------DA-LKLANEGKV---K-EAQAAAEQLKTTRNAYIQKYLQTISNEQRASKVLGIVFFLFLLMWCPFFITNITLVLCDSCNTTLQMLLEIFVWIGYVSSGVNPLVYTLFNKTFRDAFGRYITCNYR----- | |||||||||||||||||||
| 8 | 2rh1A | 0.26 | 0.27 | 0.87 | 4.28 | Download | ----------------------------------------------DEVWVVGMGIVMSLIVLAIVFGNVLVITAIAKFERLQTVTNYFITSLACADLVMGLAVVPFGAAHILMKMWTFGNFWCEFWTSIDVLCVTASIETLCVIAVDRYFAITSPFKYQSLLTKNKARVIILMVWIVSGLTSFLPIQMHWYRATHAEETCCDFFTNQAYAIASSIVSFYVPLVIMVFVYSRVFQEAKRQLNIFEMLRIDEGSPSLNAAKSELDKAIGRNTNGVITKDEAEKLFNQDVDAAVRGILRNAKLKPVYDSLDFQMGETGVAGFTNSLRMLQQKRWDEAAVNLAKSRWYNQTPNRAKRVITTFRTGTWDAYKFCLKEHKALKTLG----IIMGTFTLCWLPFFIVNIVHVIQDN--LIRKEVYILLNWIGYVNSGFNPLIYC-RSPDFRIAFQELLCL-------- | |||||||||||||||||||
| 9 | 5wiuA | 0.30 | 0.30 | 0.81 | 2.79 | Download | --------------------------------------------------GAAALVGGVLLIGAVLAGNSLVCVSVATERALQTPTNSFIVSLAAADLLLALLVLPLFVYSEVQGAWLLSPRLCDALMAMDVMLCTASIFNLCAISVDRFVAVAVPLRYNRQGGSRRQLLLIGATWLLSAAVAAPVLCGL------NDPAVCRL-EDRDYVVYSSVCSFFLPCPLMLLLYWATFRGLQRWEVARRADLEDNWETLNDNLKVIEKADNAAQVKDALTKMRAAALDAQKATPPKLEDKSPPEMKDFRHGFDILVGQIDDALK---------------------LANEGKVKEAQAAAEQLKTTRNAYIQKYLAKITGRERKAMRVLPVVVGAFLLCWTPFFVVHITQALCPA-CSVPPRLVSAVTWLGYVNSALNPVIYTVFNAEFRNVFRKA----------- | |||||||||||||||||||
| 10 | 5dsgA | 0.22 | 0.23 | 0.84 | 2.05 | Download | --------------------------------------GPSSHNRYETVEMVFIATVTGSLSLVTVVGNILVMLSIKVNRQLQTVNNYFLFSLACADLIIGAFSMNLYTVYIIKGYWPLGAVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPARRTTKMAGLMIAAAWVLSFVLWAPAILFWGKRTVPDNQCFIQFLSNPAVTFGTAIAAFYLPVVIMTVLYIHISLASRSRVNIFEMLRIDEEAEKLFNQDVDAAVRGILRNAKLKPV--------------------------YDSLDAVRRAALINMVFQMGETGVAGFTNSLRMLQQKRWDEAAVNLAKSRWYNQTPNRAKRVITTFRTGTWDAYRKVTRTIFAILLAFILTWTPYNVMVLVNTFCQSC--IPDTVWSIGYWLCYVNSTINPACYALCNATFKKTFRHLLLC-------- | |||||||||||||||||||
| ||||||||||||||||||||||||||
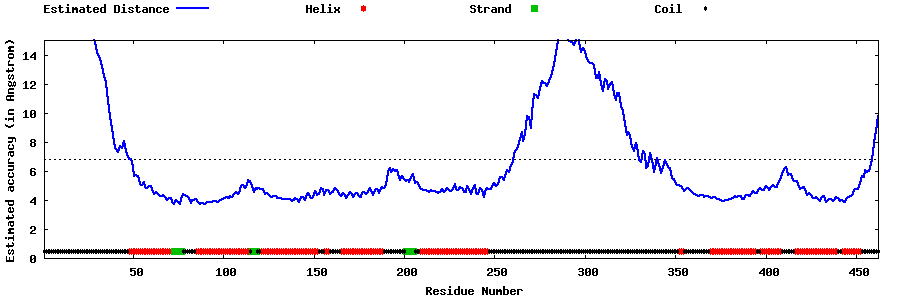
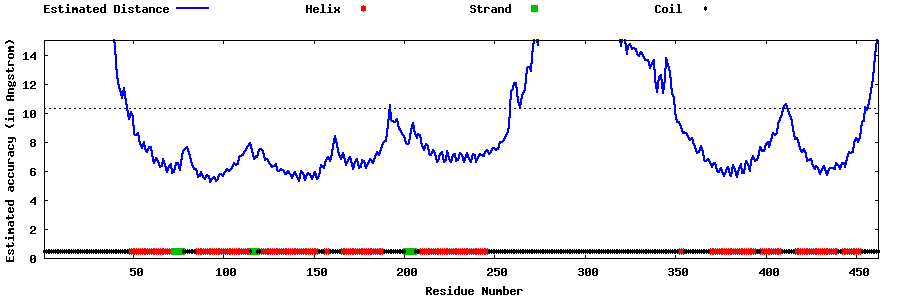
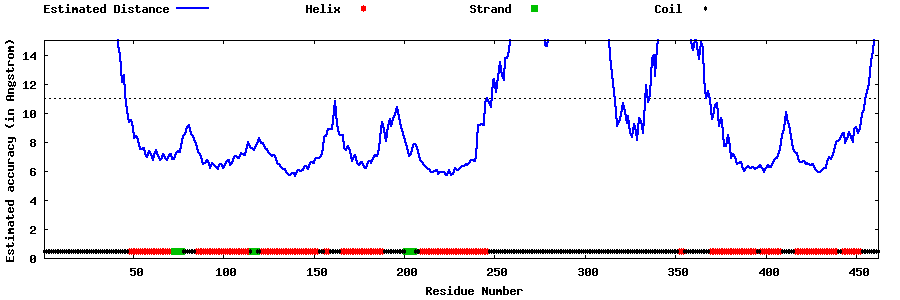
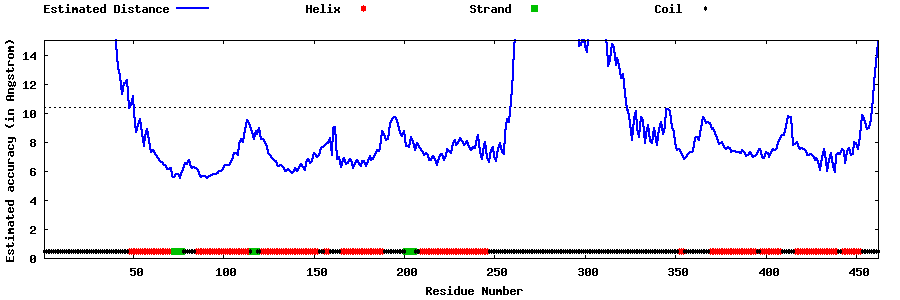
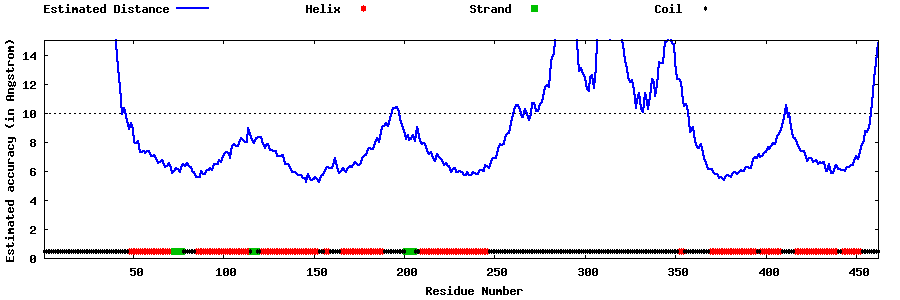
| Generated 3D models | Estimated local accuracy of models | ||
 | |||
|
|
|||
 | |||
|
| |||
 | |||
|
| |||
 | |||
|
| |||
 | |||
|
| |||
