
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MQQNNSVPEFILLGLTQDPLRQKIVFVIFLIFYMGTVVGNMLIIVTIKSSRTLGSPMYFFLFYLSFADSCFSTSTAPRLIVDALSEKKIITYNECMTQVFALHLFGCMEIFVLILMAVDRYVAICKPLRYPTIMSQQVCIILIVLAWIGSLIHSTAQIILALRLPFCGPYLIDHYCCDLQPLLKLACMDTYMINLLLVSNSGAICSSSFMILIISYIVILHSLRNHSAKGKKKALSACTSHIIVVILFFGPCIFIYTRPPTTFPMDKMVAVFYTIGTPFLNPLIYTLRNAEVKNAMRKLWHGKIISENKG | |
| CCCCCCSSSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHSSSSSCCCCCCCCHHHHHHHHHHHHHHHHCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCHHCCCHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCSSCCCHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHCSSSSSCCCCCCCCCHHHHHHHHHCCHHHCCCHHHCCCCHHHHHHHHHHHHHCCCCCCCC | |
| 9999721134672599981258999999999999999978875441210799999789998869998651204575899998851896786899999999999999989999999986528873722026002677489999999999999999999999633788898836776418389888821230423101443432999999999999999999983435731222898888889991657631520488588999964120035664403300037433462999999999997215645589 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MQQNNSVPEFILLGLTQDPLRQKIVFVIFLIFYMGTVVGNMLIIVTIKSSRTLGSPMYFFLFYLSFADSCFSTSTAPRLIVDALSEKKIITYNECMTQVFALHLFGCMEIFVLILMAVDRYVAICKPLRYPTIMSQQVCIILIVLAWIGSLIHSTAQIILALRLPFCGPYLIDHYCCDLQPLLKLACMDTYMINLLLVSNSGAICSSSFMILIISYIVILHSLRNHSAKGKKKALSACTSHIIVVILFFGPCIFIYTRPPTTFPMDKMVAVFYTIGTPFLNPLIYTLRNAEVKNAMRKLWHGKIISENKG | |
| 8744220000000000424500100003133323323332330000020043030000100230012001100000020000002532100050000000110331131020002003000000022110100003310000012013102301300131023030001022000100222003000020230003002301320231033133112100200132146122200100300210020132101000000333133000100310231033013000020440230023003430325668 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCSSSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHSSSSSCCCCCCCCHHHHHHHHHHHHHHHHCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCHHCCCHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCSSCCCHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHCSSSSSCCCCCCCCCHHHHHHHHHCCHHHCCCHHHCCCCHHHHHHHHHHHHHCCCCCCCC MQQNNSVPEFILLGLTQDPLRQKIVFVIFLIFYMGTVVGNMLIIVTIKSSRTLGSPMYFFLFYLSFADSCFSTSTAPRLIVDALSEKKIITYNECMTQVFALHLFGCMEIFVLILMAVDRYVAICKPLRYPTIMSQQVCIILIVLAWIGSLIHSTAQIILALRLPFCGPYLIDHYCCDLQPLLKLACMDTYMINLLLVSNSGAICSSSFMILIISYIVILHSLRNHSAKGKKKALSACTSHIIVVILFFGPCIFIYTRPPTTFPMDKMVAVFYTIGTPFLNPLIYTLRNAEVKNAMRKLWHGKIISENKG | |||||||||||||||||||||||||
| 1 | 3emlA | 0.18 | 0.21 | 0.88 | 3.41 | Download | ------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVPMNYMVYFN-----------FFACVLVPLLLMLGVYLRIFLAARQLVHAAKSLAIIVGLFALCWLPLHIIN-CFTFFCPDCSHAWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ--- | |||||||||||||||||||
| 2 | 5tgzA | 0.21 | 0.23 | 0.89 | 2.25 | Download | -ENFMDIECF----MVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRK-DSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLL--------GWNCEK---------LQSVCSDIFHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARELAKTLVLILVVLIICWGPLLAIMVKMNKLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSM----------- | |||||||||||||||||||
| 3 | 5tgzA | 0.18 | 0.23 | 0.89 | 2.08 | Download | -GGRGENFMDIECFMVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFH-VFHRKDSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLCEKLQSVC----------------------SDIFPHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHADIELAKTLVLILVVLIICWGPLLAIMVGKMNLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF---------- | |||||||||||||||||||
| 4 | 4djh | 0.17 | 0.27 | 0.90 | 1.54 | Download | -----------------SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRYTKMKTATNIYIFNLALADALVTT-TMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVR---EDVDVIECSLQFPDD---DYSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP-------- | |||||||||||||||||||
| 5 | 4yay | 0.16 | 0.24 | 0.90 | 1.22 | Download | TTRNAYIQKYLILNSSDCNYIFVMIPTLYSIIFVVGIFGNSLVVIVIYFYMKLKTVASVFLLNLALADLCFLLTLPLWAVYTAMEYRWPFGNYLCKIASASVSFNLYASVFLLTCLSIDRYLAIVHPMKSRLRRTMLVAKVTCIIIWLLAGLASLPAIIHRNVFF-------IITVCAFHYE--------TLPIGLGLTKNILGFLFPFLIILTSYTLIWKALK-----KNDDIFKIIMAIVLFFFFSWIPHQIFTFLDVLIVDTAMPITICIAYFNNCLNPLFYGFLGKKFKRYFLQLL---------- | |||||||||||||||||||
| 6 | 3emlA | 0.19 | 0.21 | 0.89 | 3.57 | Download | -------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCFTFFCPDCSHAWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ--- | |||||||||||||||||||
| 7 | 4iaq | 0.20 | 0.24 | 0.84 | 1.74 | Download | --------------------WKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPF-FWRQASECVVNT--------------------DHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIADRERKATKTLGIILGAFIVCWLPFFIISLVMPIH-LAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK------- | |||||||||||||||||||
| 8 | 2z73A | 0.18 | 0.23 | 0.96 | 2.94 | Download | WYNPSIVVHPHWREFDQVPAVYYSLGIFIGICGIIGCGGNGIVIYLFTKTKSLQTPANMFIINLAFSDFTFSLVNGPLMTISCFLKKWIFGFAACKVYGFIGGIFGFMSIMTMAMISIDRYNVIGRPMAASKKMSHRRAFIMIIFVWLWSVLWAIGPIFGTLEGVLC------NCSFDY-----ISRDSTTRSNILCMFILGLIIFFCYFNIVMNHEKEMAAMAKRLNAKEAKISIVIVSQFLLSWSPYAVVALLAQFGPWVTPYAAQLPVMFAKASAIHNPMIYSVSHPKFREAISQTFPWVLTCCQFD | |||||||||||||||||||
| 9 | 5tgzA | 0.21 | 0.23 | 0.89 | 4.74 | Download | GENFMDIECFMVL----NPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVF-HRKDSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLG---------NCEK---------LQSVCSDIFHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDMDIELAKTLVLILVVLIICWGPLLAIMVYDVFGKMTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF---------- | |||||||||||||||||||
| 10 | 2ydoA | 0.16 | 0.20 | 0.93 | 5.58 | Download | ---------------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSAAAADILVGVLAIPFAIA--ISTGFCAACHGCLFIACFVLVLTASSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQPKEGKAHSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRLKQMESTLQKEVHAAKSLAIIVGLFALCCFTFFCPDCSHAPLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQQEP | |||||||||||||||||||
| ||||||||||||||||||||||||||
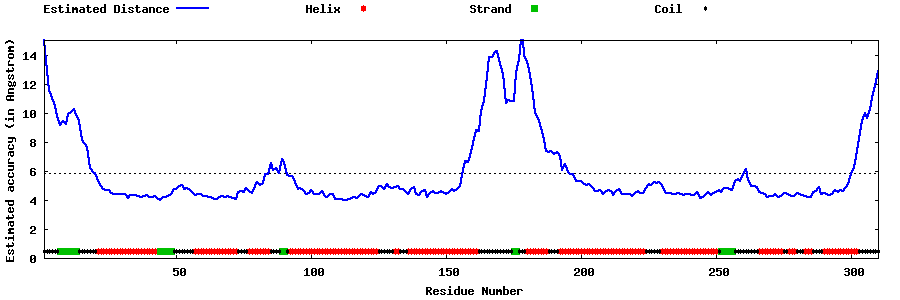
| Generated 3D models | Estimated local accuracy of models | ||
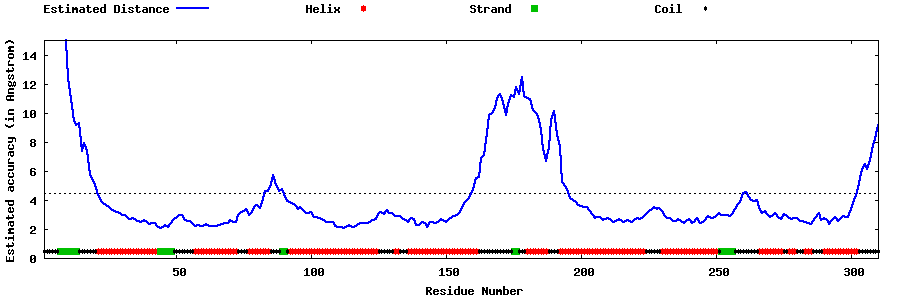 | |||
|
|
|||
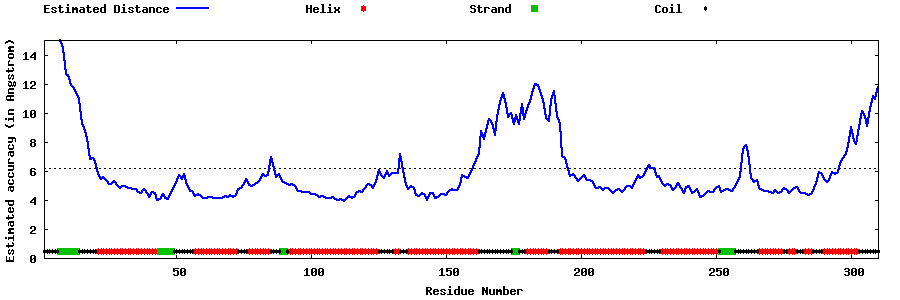 | |||
|
| |||
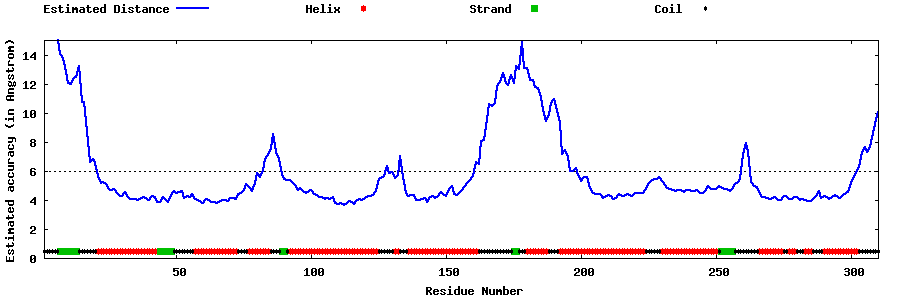 | |||
|
| |||
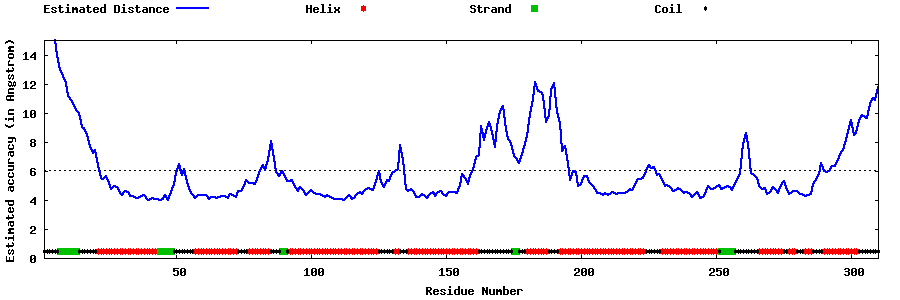 | |||
|
| |||
 | |||
|
| |||
