
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MDPQNYSLVSEFVLHGLCTSRHLQNFFFIFFFGVYVAIMLGNLLILVTVISDPCLHSSPMYFLLGNLAFLDMWLASFATPKMIRDFLSDQKLISFGGCMAQIFFLHFTGGAEMVLLVSMAYDRYVAICKPLHYMTLMSWQTCIRLVLASWVVGFVHSISQVAFTVNLPYCGPNEVDSFFCDLPLVIKLACMDTYVLGIIMISDSGLLSLSCFLLLLISYTVILLAIRQRAAGSTSKALSTCSAHIMVVTLFFGPCIFVYVRPFSRFSVDKLLSVFYTIFTPLLNPIIYTLRNEEMKAAMKKLQNRRVTFQ | |
| CCCCCCCSSSSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHSSSSSCCCCCCCCCHHHHHHHHHHHHHHHHCCCHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCHHCCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCSSCCCHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHHCCSSSSSCCCCCCCCCHHHHHHHHHHHHHCCCCHHHCCCCHHHHHHHHHHHHHCCCCC | |
| 9987887005888926999822589999999999999998788736634517877999819987659988664333360999998716996783899999999999999999999999986518874721025221787599999999999999999999999532899898836777518388787840340644544777777999999999999999999995113731221999898879993315630544688588999973133478886156400027433562999999999997127679 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MDPQNYSLVSEFVLHGLCTSRHLQNFFFIFFFGVYVAIMLGNLLILVTVISDPCLHSSPMYFLLGNLAFLDMWLASFATPKMIRDFLSDQKLISFGGCMAQIFFLHFTGGAEMVLLVSMAYDRYVAICKPLHYMTLMSWQTCIRLVLASWVVGFVHSISQVAFTVNLPYCGPNEVDSFFCDLPLVIKLACMDTYVLGIIMISDSGLLSLSCFLLLLISYTVILLAIRQRAAGSTSKALSTCSAHIMVVTLFFGPCIFVYVRPFSRFSVDKLLSVFYTIFTPLLNPIIYTLRNEEMKAAMKKLQNRRVTFQ | |
| 8666242200000000004244001000131333233233323300000200330312000100230012001100000020000002532100050000000110331131020002003100000022110100013310000012013102201300131023030000122000100221003000020230003002301310231033133112100200132046122200100300210030232101000000333233011000310331033113000020540230033014430538 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCSSSSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHSSSSSCCCCCCCCCHHHHHHHHHHHHHHHHCCCHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCHHCCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCSSCCCHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHHCCSSSSSCCCCCCCCCHHHHHHHHHHHHHCCCCHHHCCCCHHHHHHHHHHHHHCCCCC MDPQNYSLVSEFVLHGLCTSRHLQNFFFIFFFGVYVAIMLGNLLILVTVISDPCLHSSPMYFLLGNLAFLDMWLASFATPKMIRDFLSDQKLISFGGCMAQIFFLHFTGGAEMVLLVSMAYDRYVAICKPLHYMTLMSWQTCIRLVLASWVVGFVHSISQVAFTVNLPYCGPNEVDSFFCDLPLVIKLACMDTYVLGIIMISDSGLLSLSCFLLLLISYTVILLAIRQRAAGSTSKALSTCSAHIMVVTLFFGPCIFVYVRPFSRFSVDKLLSVFYTIFTPLLNPIIYTLRNEEMKAAMKKLQNRRVTFQ | |||||||||||||||||||||||||
| 1 | 3emlA | 0.22 | 0.22 | 0.88 | 3.36 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQN-VTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVPMNYMVYFN-----------FFACVLVPLLLMLGVYLRIFLAARQLVHAAKSLAIIVGLFALCWLPLH-IINCFTFFCPDCSHAWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ | |||||||||||||||||||
| 2 | 5tgzA | 0.19 | 0.23 | 0.90 | 2.34 | Download | -RGENFMDIECF----MVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCRPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRK-DSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVL--------PLLGWNCEKL---------QSVCSDIFHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARELAKTLVLILVVLIICWGPLLAIMVKMNKLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSM-------- | |||||||||||||||||||
| 3 | 5tgzA | 0.17 | 0.23 | 0.88 | 2.08 | Download | ----------GGRGENFMDIPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCRPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRKD-SRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLCEKLQSVC-------------------SDIFPHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHQARMDIELAKTLVLILVVLIICWGPLLAIMVGKMNLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF------- | |||||||||||||||||||
| 4 | 4djh | 0.15 | 0.27 | 0.90 | 1.55 | Download | -------------------SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRYTKM-KTATNIYIFNLALADALVTT-TMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVR---EDVDVIECSLQFPDD---DYSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSLSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP----- | |||||||||||||||||||
| 5 | 4yay | 0.15 | 0.23 | 0.91 | 1.23 | Download | LKTTRNAYIQKYLILNSSDCNYIFVMIPTLYSIIFVVGIFGNSLVVIVIYFYMKLKT-VASVFLLNLALADLCFLLTLPLWAVYTAMEYRWPFGNYLCKIASASVSFNLYASVFLLTCLSIDRYLAIVHPMKSRLRRTMLVAKVTCIIIWLLAGLASLPAIIHRNVFF-------IITVCAFHYE--------TLPIGLGLTKNILGFLFPFLIILTSYTLIWKALK-----KNDDIFKIIMAIVLFFFFSWIPHQIFTFLDVLIVDTAMPITICIAYFNNCLNPLFYGFLGKKFKRYFLQLL------- | |||||||||||||||||||
| 6 | 5tgzA | 0.18 | 0.23 | 0.91 | 3.58 | Download | GRGENFMDIECFMVLN----PSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCRPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRK-DSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAV--------LPLLGWNCEK--------LQSVCSDIFPHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQAIELAKTLVLILVVLIICWGPLLAIMVYDVFLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF------- | |||||||||||||||||||
| 7 | 4iaq | 0.21 | 0.25 | 0.85 | 1.74 | Download | --------------------LPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLH-TPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFFW-RQASECVVNT-----------------D---HILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIADRERKATKTLGIILGAFIVCWLPFFIISLVMPIH-LAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK---- | |||||||||||||||||||
| 8 | 4ea3A | 0.21 | 0.23 | 0.82 | 2.92 | Download | -------------------PLGLKVTIVGLYLAVCVGGLLGNCLVMYVILRHTKMKT-ATNIYIFNLALADTLVLLT-LPFQGTDILLGFWPFGNALCKTVIAIDYYNMFTSTFTLTAMSVDRYVAICHPTSSKAQAVNVAIWALASVVGVPVAIMGSAQ----------VEDEEIECLVEIP----------TPQDYWGPVFAICIFLFSFLVISVCYSLMIRRLRGVRLLSGSAVFVGCWTPVQVFVLAQGLG----VQPSSTAVAILRFCTALGYVNSCLNPILYAFLDENFKACFR---------- | |||||||||||||||||||
| 9 | 5tgzA | 0.18 | 0.23 | 0.90 | 4.76 | Download | GRGENFMDIECFMVL----NPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCRPSYHFIGSLAVADLLGSVIFVYSFIDFHVF-HRKDSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLG---------NCEK---------LQSVCSDIFHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQAIELAKTLVLILVVLIICWGPLLAIMVYDVFGKMTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF------- | |||||||||||||||||||
| 10 | 2ydoA | 0.20 | 0.23 | 0.92 | 5.40 | Download | -----------------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQN-VTNYFVVSAAAADILVGVLAIPFAIA--ISTGFCAACHGCLFIACFVLVLTASSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQPKEGKAHSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQKQMESTLQKEVHAAKSLAIIVGLFALCCFTFFCPDCSHAPLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ | |||||||||||||||||||
| ||||||||||||||||||||||||||
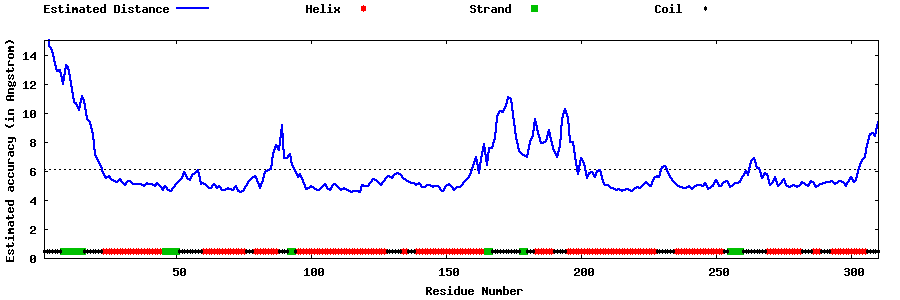
| Generated 3D models | Estimated local accuracy of models | ||
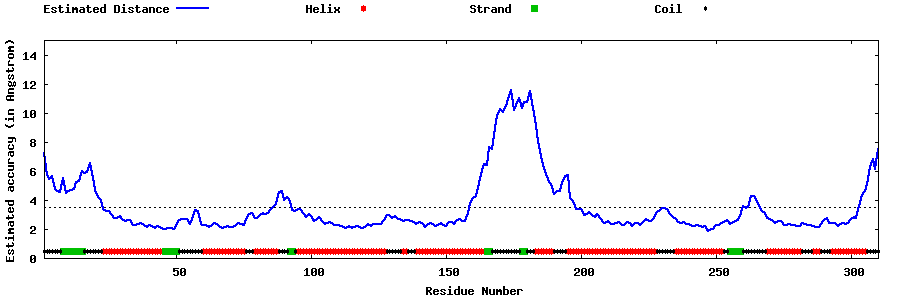 | |||
|
|
|||
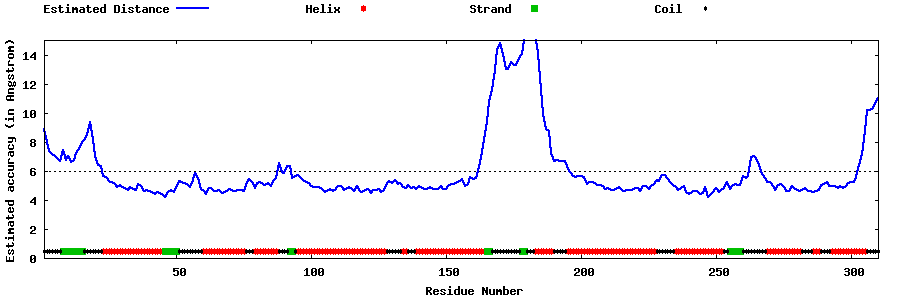 | |||
|
| |||
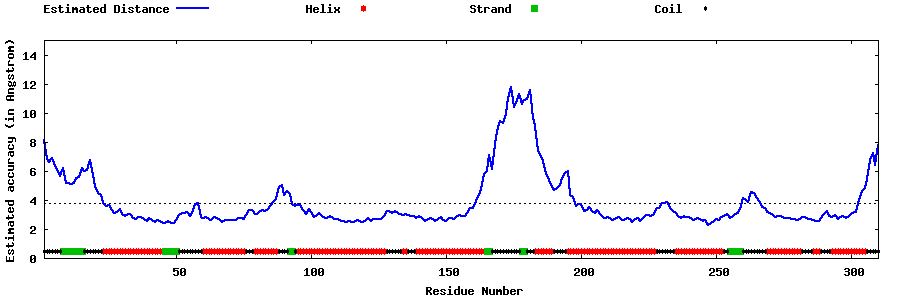 | |||
|
| |||
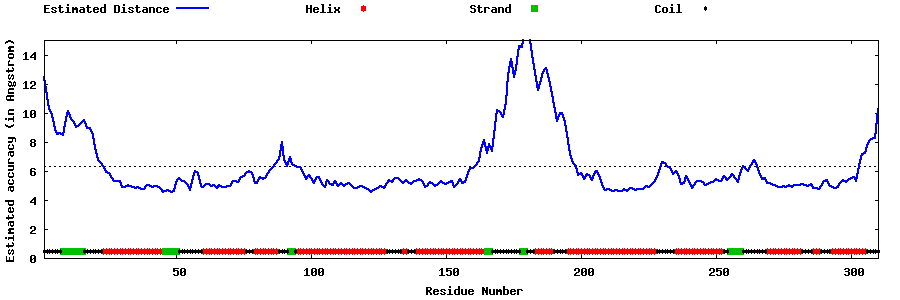 | |||
|
| |||
 | |||
|
| |||
