
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MVTEFIFLGLSDSQELQTFLFMLFFVFYGGIVFGNLLIVITVVSDSHLHSPMYFLLANLSLIDLSLSSVTAPKMITDFFSQRKVISFKGCLVQIFLLHFFGGSEMVILIAMGFDRYIAICKPLHYTTIMCGNACVGIMAVTWGIGFLHSVSQLAFAVHLLFCGPNEVDSFYCDLPRVIKLACTDTYRLDIMVIANSGVLTVCSFVLLIISYTIILMTIQHRPLDKSSKALSTLTAHITVVLLFFGPCVFIYAWPFPIKSLDKFLAVFYSVITPLLNPIIYTLRNKDMKTAIRQLRKWDAHSSVKF | |
| CSSSSSSCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHSSSSSCCCCCCCCHHHHHHHHHHHHHHHHCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCHHCCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCSSCCCHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHCSSSSSCCCCCCCCCHHHHHHHHHHHHHHCCCHHHCCCCHHHHHHHHHHHHHCCCCCCCC | |
| 91279853799883168999999999999999878875441220799999789998749988665433370999999843897786899999999999999999999999986517862623045121687599999999999999999999999530899898836686318289888830232355655776765999999999999999999999674733140999998879992447630531488688999962253367875324401037443562999999999997005664589 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MVTEFIFLGLSDSQELQTFLFMLFFVFYGGIVFGNLLIVITVVSDSHLHSPMYFLLANLSLIDLSLSSVTAPKMITDFFSQRKVISFKGCLVQIFLLHFFGGSEMVILIAMGFDRYIAICKPLHYTTIMCGNACVGIMAVTWGIGFLHSVSQLAFAVHLLFCGPNEVDSFYCDLPRVIKLACTDTYRLDIMVIANSGVLTVCSFVLLIISYTIILMTIQHRPLDKSSKALSTLTAHITVVLLFFGPCVFIYAWPFPIKSLDKFLAVFYSVITPLLNPIIYTLRNKDMKTAIRQLRKWDAHSSVKF | |
| 63100000000424400100013133323323332330000010043030000000230012001100000020000002532100050000000110331131020002003100000022110200013310000012013102201300131023030000122000100221003000020230103002301310231033133112100200132146122200100300210030232101000000333233011100310231033113000010540230033014431435753 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CSSSSSSCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHSSSSSCCCCCCCCHHHHHHHHHHHHHHHHCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCHHCCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCSSCCCHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHCSSSSSCCCCCCCCCHHHHHHHHHHHHHHCCCHHHCCCCHHHHHHHHHHHHHCCCCCCCC MVTEFIFLGLSDSQELQTFLFMLFFVFYGGIVFGNLLIVITVVSDSHLHSPMYFLLANLSLIDLSLSSVTAPKMITDFFSQRKVISFKGCLVQIFLLHFFGGSEMVILIAMGFDRYIAICKPLHYTTIMCGNACVGIMAVTWGIGFLHSVSQLAFAVHLLFCGPNEVDSFYCDLPRVIKLACTDTYRLDIMVIANSGVLTVCSFVLLIISYTIILMTIQHRPLDKSSKALSTLTAHITVVLLFFGPCVFIYAWPFPIKSLDKFLAVFYSVITPLLNPIIYTLRNKDMKTAIRQLRKWDAHSSVKF | |||||||||||||||||||||||||
| 1 | 3emlA | 0.20 | 0.23 | 0.90 | 3.42 | Download | -------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVPMNYMVYF-----------NFFACVLVPLLLMLGVYLRIFLAARQLVHAAKSLAIIVGLFALCWLPLH-IINCFTFFCPDCAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ--- | |||||||||||||||||||
| 2 | 5tgzA | 0.21 | 0.27 | 0.87 | 2.18 | Download | ------------NPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDF-HVFHRKDSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVL--------PLLGWNCEKL---------QSVCSDIFHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARELAKTLVLILVVLIICWGPLLAIMVKMNKLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSM----------- | |||||||||||||||||||
| 3 | 4iaqA | 0.20 | 0.25 | 0.82 | 2.09 | Download | -----YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGR----WVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISILYTVYSTVGAF---------------------------------------YFPTLLLIALYGRIYVEARSRIIQMAARERKATKTLGIILGAFIVCWLPFFIISLVMPLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK------- | |||||||||||||||||||
| 4 | 4ib4 | 0.18 | 0.23 | 0.90 | 1.54 | Download | ----------EEQGNKLHWAALLILMVIIPTIGGNTLVILAVSLEKKLQYATNYFLMSLAVADLLVGLFVMPIALLTIMEAMWPLPLVLCPAWLFLDVLFSTASIWHLCAISVDRYIAIKKPIQANQYNSRATAFIKITVVWLISIGIAIPVPIKG-IET-----NPNNITCVLTK---------ERFGDFMLFGSLAAFFTPLAIMIVTYFLTIHALQKKAADNEQRASKVLGIVFFLFLLMWCPFFITNITLVLCQQMLLEIFVWIGYVSSGVNPLVYTLFNKTFRDAFGRYITCNYR----- | |||||||||||||||||||
| 5 | 4yay | 0.17 | 0.23 | 0.90 | 1.21 | Download | YIQKYLILNSSDCNYIFVMIPTLYSIIFVVGIFGNSLVVIVIYFYMKLKTVASVFLLNLALADLCFLLTLPLWAVYTAMEYRWPFGNYLCKIASASVSFNLYASVFLLTCLSIDRYLAIVHPMKSRLRRTMLVAKVTCIIIWLLAGLASLPAIIHRNVFF-------IITVCAFHYE------T--LPIGLGLTKNILGFLFPFLIILTSYTLIWKALK-----KNDDIFKIIMAIVLFFFFSWIPHQIFTFLDVLIVDTAMPITICIAYFNNCLNPLFYGFLGKKFKRYFLQLL---------- | |||||||||||||||||||
| 6 | 3emlA | 0.21 | 0.23 | 0.90 | 3.53 | Download | --------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQVHAAKSLAIIVGLFALCWLPLHII-NCFTFFCPDCSHAWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ--- | |||||||||||||||||||
| 7 | 4iaq | 0.21 | 0.27 | 0.86 | 1.71 | Download | --------------PWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPF-FWRQASE----------CVVN----------TDHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIAARERKATKTLGIILGAFIVCWLPFFIISLVMPIH-LAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK------- | |||||||||||||||||||
| 8 | 4buoA | 0.17 | 0.22 | 0.90 | 2.81 | Download | -NSD---LDVNTDIYSKVLVTAIYLALFVVGTVGNSVTLFTLARKKSLQSTVDYYLGSLALSDLLILLLAMPVELYNFIWVHHPWAFAGCRGYYFLRDACTYATALNVVSLSVELYLAICHPFKAKTLMSRSRTKKFISAIWLASALLAIPMLFTMGLQNLSGDGTHPGVCTPI--------VDTATLKVVIQVNTFMSFLFPMLVASILNTVIANKLTVMVHQAVVIAFVVCWLPYHVRRLMFCYI-------SDEQWYFYMLTNALVYVSAAINPILYNLVSANFRQVFLSTL---------- | |||||||||||||||||||
| 9 | 5tgzA | 0.22 | 0.27 | 0.89 | 4.41 | Download | DIECFMVL----NPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVF-HRKDSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLG-------NCEKLQS-----------VCSDIFHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARELAKTLVLILVVLIICWGPLLAIMVYDVFGKMTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF---------- | |||||||||||||||||||
| 10 | 2ydoA | 0.18 | 0.23 | 0.94 | 5.54 | Download | ----------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSAAAADILVGVLAIPFAIA--ISTGFCAACHGCLFIACFVLVLTASSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQPKEGKAHSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLKQESTLQKEVHAAKSLAIIVGLFALCCFTFFCPDCSHAPLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQQEP | |||||||||||||||||||
| ||||||||||||||||||||||||||
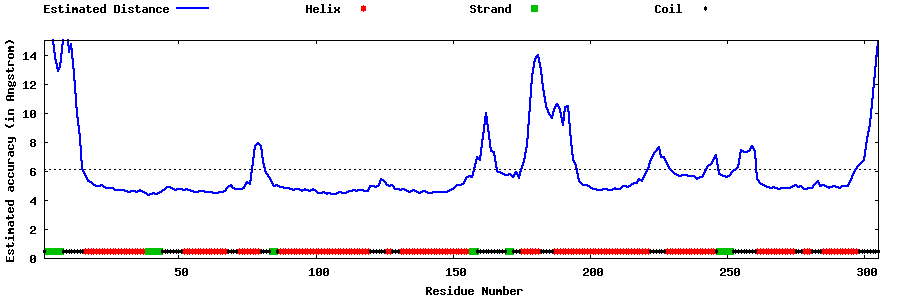
| Generated 3D models | Estimated local accuracy of models | ||
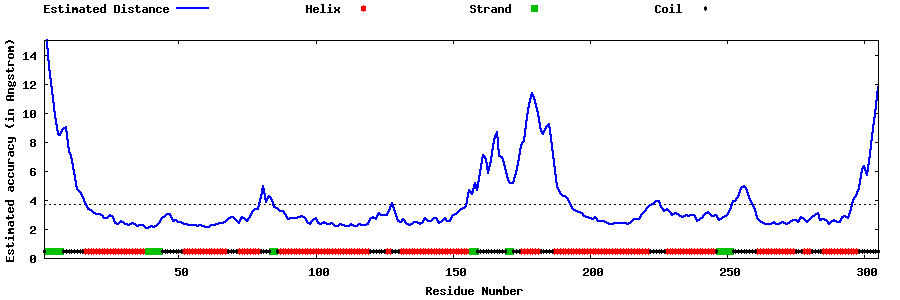 | |||
|
|
|||
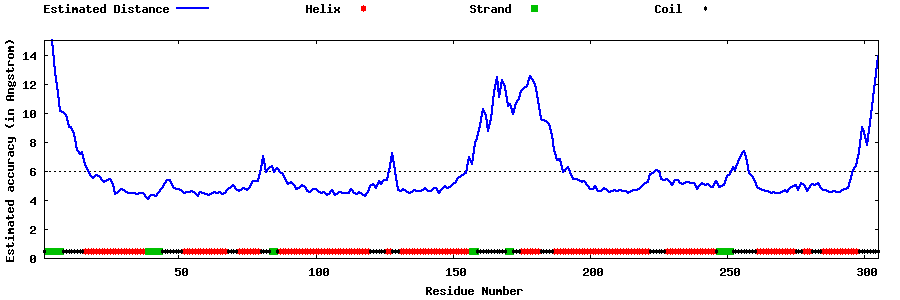 | |||
|
| |||
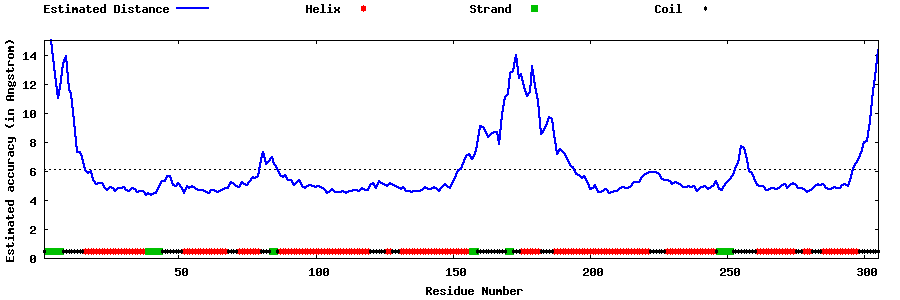 | |||
|
| |||
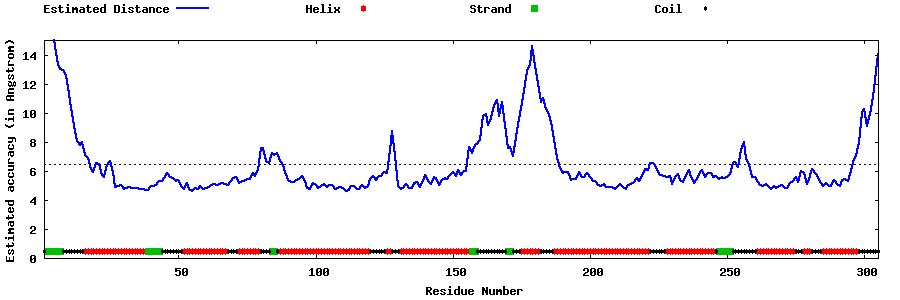 | |||
|
| |||
 | |||
|
| |||
