
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MERANHSVVSEFILLGLSKSQNLQILFFLGFSVVFVGIVLGNLLILVTVTFDSLLHTPMYFLLSNLSCIDMILASFATPKMIVDFLRERKTISWWGCYSQMFFMHLLGGSEMMLLVAMAIDRYVAICKPLHYMTIMSPRVLTGLLLSSYAVGFVHSSSQMAFMLTLPFCGPNVIDSFFCDLPLVIKLACKDTYILQLLVIADSGLLSLVCFLLLLVSYGVIIFSVRYRAASRSSKAFSTLSAHITVVTLFFAPCVFIYVWPFSRYSVDKILSVFYTIFTPLLNPIIYTLRNQEVKAAIKKRLCI | |
| CCCCCCCSSSSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHSSSSSCCCCCCCCHHHHHHHHHHHHHHHHCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCHHCCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCSSCCCHHHHHHHHCCCCHHHSSHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHHHCSSSSSCCCCCCCCCCCSSHHHHHCHHHHCCCHHHCCCCHHHHHHHHHHHCC | |
| 9986797315778806999812489999999999999998688755512127999997899988699886502145758999987438967868999999999999999999999999865178746110261036775999999999999999999999991427898988367764282898888303404331002224549999999999999999999941147312218998888899926577315203884889999750001456653254010373334619999999998439 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MERANHSVVSEFILLGLSKSQNLQILFFLGFSVVFVGIVLGNLLILVTVTFDSLLHTPMYFLLSNLSCIDMILASFATPKMIVDFLRERKTISWWGCYSQMFFMHLLGGSEMMLLVAMAIDRYVAICKPLHYMTIMSPRVLTGLLLSSYAVGFVHSSSQMAFMLTLPFCGPNVIDSFFCDLPLVIKLACKDTYILQLLVIADSGLLSLVCFLLLLVSYGVIIFSVRYRAASRSSKAFSTLSAHITVVTLFFAPCVFIYVWPFSRYSVDKILSVFYTIFTPLLNPIIYTLRNQEVKAAIKKRLCI | |
| 8566232300000000004244001000131333233233323300000200430300001002300120011000000200000025321000500000001103311310200020031000000221102000133100000120131023013002310230300001220001002210030000202300030023013102310331331121002001321461222001003002100302321010000003332330111003102310331130000205402300332116 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCSSSSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHSSSSSCCCCCCCCHHHHHHHHHHHHHHHHCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCHHCCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCSSCCCHHHHHHHHCCCCHHHSSHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHHHCSSSSSCCCCCCCCCCCSSHHHHHCHHHHCCCHHHCCCCHHHHHHHHHHHCC MERANHSVVSEFILLGLSKSQNLQILFFLGFSVVFVGIVLGNLLILVTVTFDSLLHTPMYFLLSNLSCIDMILASFATPKMIVDFLRERKTISWWGCYSQMFFMHLLGGSEMMLLVAMAIDRYVAICKPLHYMTIMSPRVLTGLLLSSYAVGFVHSSSQMAFMLTLPFCGPNVIDSFFCDLPLVIKLACKDTYILQLLVIADSGLLSLVCFLLLLVSYGVIIFSVRYRAASRSSKAFSTLSAHITVVTLFFAPCVFIYVWPFSRYSVDKILSVFYTIFTPLLNPIIYTLRNQEVKAAIKKRLCI | |||||||||||||||||||||||||
| 1 | 3emlA | 0.22 | 0.25 | 0.88 | 2.92 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVPMNYMVYFNF-----------FACVLVPLLLMLGVYLRIFLAARQLVHAAKSLAIIVGLFALCWLPLHIIN-CFTFFCPDCSHAWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRV | |||||||||||||||||||
| 2 | 5tgzA | 0.19 | 0.25 | 0.92 | 2.25 | Download | -RGENFMDIECF----MVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRK-DSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVL--------PLLGWNCEKL---------QSVCSDIFHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARELAKTLVLILVVLIICWGPLLAIMVKMNKLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF-- | |||||||||||||||||||
| 3 | 5tgzA | 0.15 | 0.25 | 0.92 | 2.09 | Download | ---GGRGENFMDIECFMVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFH-VFHRKDSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLCEKLQSVC-------------------SDIFPHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARMDIELAKTLVLILVVLIICWGPLLAIKMNLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF-- | |||||||||||||||||||
| 4 | 4djh | 0.15 | 0.22 | 0.91 | 1.54 | Download | -------------------SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRYTKMKTATNIYIFNLALADALVTT-TMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVR---EDVDVIECSLQFPDD---DYSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSLSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP | |||||||||||||||||||
| 5 | 4yay | 0.17 | 0.23 | 0.93 | 1.23 | Download | LKTTRNAYIQKYLILNSSDCNYIFVMIPTLYSIIFVVGIFGNSLVVIVIYFYMKLKTVASVFLLNLALADLCFLLTLPLWAVYTAMEYRWPFGNYLCKIASASVSFNLYASVFLLTCLSIDRYLAIVHPMKSRLRRTMLVAKVTCIIIWLLAGLASLPAIIHRNVFF-------IITVCAFHYE--------TLPIGLGLTKNILGFLFPFLIILTSYTLIWKALK-----KNDDIFKIIMAIVLFFFFSWIPHQIFTFLDLGRVDTAMPITICIAYFNNCLNPLFYGFLGKKFKRYFLQLL-- | |||||||||||||||||||
| 6 | 5tgzA | 0.19 | 0.25 | 0.92 | 3.70 | Download | GRGENFMDIECFMVLN----PSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRK-DSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAV--------LPLLGWNCEK--------LQSVCSDIFPHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQAIELAKTLVLILVVLIICWGPLLAIMVYDVFLIKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF-- | |||||||||||||||||||
| 7 | 4iaq | 0.22 | 0.23 | 0.86 | 1.72 | Download | ---------------------PWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFF-WRQASECVVN--------------------TDHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIADRERKATKTLGIILGAFIVCWLPFFIISLVMPIHLAI-FDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIR- | |||||||||||||||||||
| 8 | 2z73A | 0.17 | 0.21 | 0.95 | 2.81 | Download | -ETWNPSIVVHPHWREFDQPDAVYYSLGIFIGICGIIGCGGNGIVIYLFTKTKSLQTPANMFIINLAFSDFTFSLVNGPLMTISCFLKKWIFGFAACKVYGFIGGIFGFMSIMTMAMISIDRYNVIGRPMAASKKMSHRRAFIMIIFVWLWSVLWAIGPIFGTLEGVLC------NCSFDY-----ISRDSTTRSNILCMFILGF--FGPILIIFFCYFNIVMQAGANAEMRLAKISIVIVSQFLLSWSPYAVVALLAQFGPLEWVTAAQLPVMFAKASAIHNPMIYSVSHPKFREAISQTFPW | |||||||||||||||||||
| 9 | 5tgzA | 0.18 | 0.25 | 0.91 | 4.90 | Download | GRGENFMDIECFMVL----NPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVF-HRKDSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLG---------NCEK---------LQSVCSDIFHIDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQAIELAKTLVLILVVLIICWGPLLAIMVYDVFGKMN-FAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF-- | |||||||||||||||||||
| 10 | 2ydoA | 0.19 | 0.26 | 0.92 | 5.48 | Download | -----------------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSAAAADILVGVLAIPFAIA--ISTGFCAACHGCLFIACFVLVLTASSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQPKEGKAHSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRLKQMESTLQKEVHAAKSLAIIVGLFALCCFTFFCPDCSHAPLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRS | |||||||||||||||||||
| ||||||||||||||||||||||||||
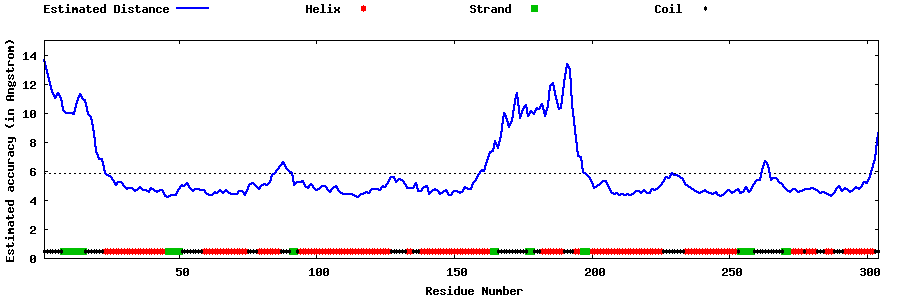
| Generated 3D models | Estimated local accuracy of models | ||
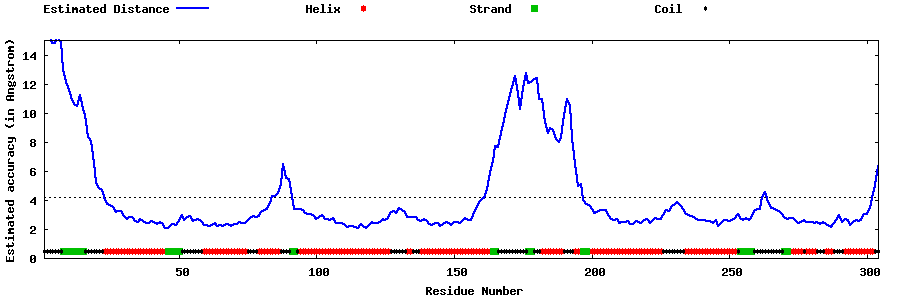 | |||
|
|
|||
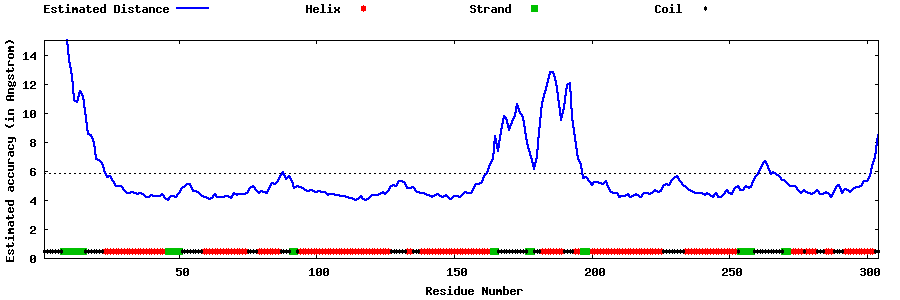 | |||
|
| |||
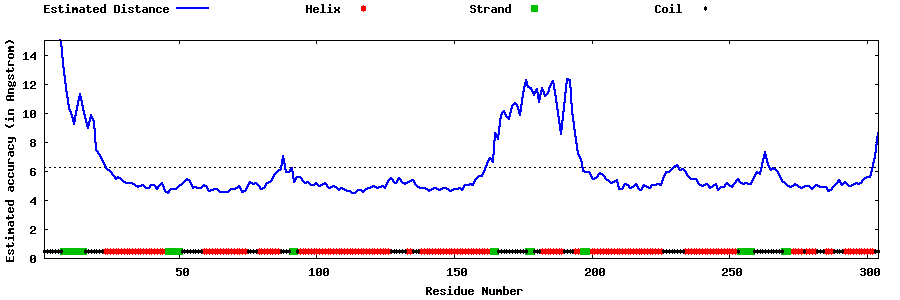 | |||
|
| |||
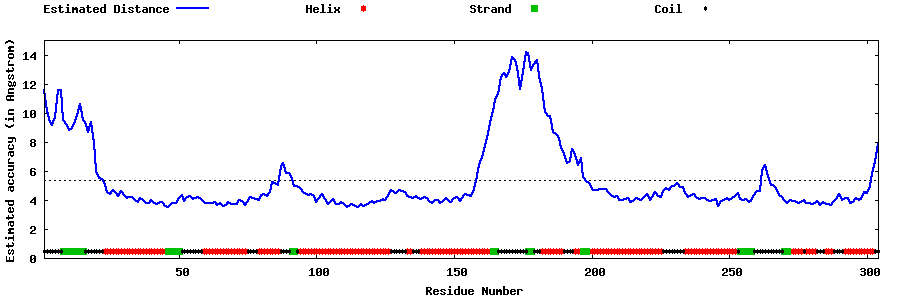 | |||
|
| |||
 | |||
|
| |||
