
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MGQHNLTVLTEFILMELTRRPELQIPLFGVFLVIYLITVVGNLTMIILTKLDSHLHTPMYFSIRHLAFVDLGNSTVICPKVLANFVVDRNTISYYACAAQLAFFLMFIISEFFILSAMAYDRYVAICNPLLYYVIMSQRLCHVLVGIQYLYSTFQALMFTIKIFTLTFCGSNVISHFYCDDVPLLPMLCSNAQEIELLSILFSVFNLISSFLIVLVSYMLILLAICQMHSAEGRKKAFSTCGSHLTVVVVFYGSLLFMYMQPNSTHFFDTDKMASVFYTLVIPMLNPLIYSLRNEEVKNAFYKLFEN | |
| CCCCCCCCCCSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSSCCCCCCCCCCCCCHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSSCCHHHCCCCHHHCCCCHHHHHHHHHHHCC | |
| 9998874221015864789825189999999999999999887999998518887772888865699874271014609998997048978858999999999999999999999999854134016330288026788999999999999999999999998555288999138642681888767046873767888889899999999999999999999980377746675332155889997999985552137478999878789889987111041233464404659899999998649 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MGQHNLTVLTEFILMELTRRPELQIPLFGVFLVIYLITVVGNLTMIILTKLDSHLHTPMYFSIRHLAFVDLGNSTVICPKVLANFVVDRNTISYYACAAQLAFFLMFIISEFFILSAMAYDRYVAICNPLLYYVIMSQRLCHVLVGIQYLYSTFQALMFTIKIFTLTFCGSNVISHFYCDDVPLLPMLCSNAQEIELLSILFSVFNLISSFLIVLVSYMLILLAICQMHSAEGRKKAFSTCGSHLTVVVVFYGSLLFMYMQPNSTHFFDTDKMASVFYTLVIPMLNPLIYSLRNEEVKNAFYKLFEN | |
| 8565230300100000004324010000230332132133323100200200130000001002000000011000000200010015422000200000000000000000100000000000000211100030033000000120022013102110020030200432100000001200030001323120110020013113303310330331011000103026323101000110310010132012000000424312444200002103200230030000213301400331177 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCCCSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSSCCCCCCCCCCCCCHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSSCCHHHCCCCHHHCCCCHHHHHHHHHHHCC MGQHNLTVLTEFILMELTRRPELQIPLFGVFLVIYLITVVGNLTMIILTKLDSHLHTPMYFSIRHLAFVDLGNSTVICPKVLANFVVDRNTISYYACAAQLAFFLMFIISEFFILSAMAYDRYVAICNPLLYYVIMSQRLCHVLVGIQYLYSTFQALMFTIKIFTLTFCGSNVISHFYCDDVPLLPMLCSNAQEIELLSILFSVFNLISSFLIVLVSYMLILLAICQMHSAEGRKKAFSTCGSHLTVVVVFYGSLLFMYMQPNSTHFFDTDKMASVFYTLVIPMLNPLIYSLRNEEVKNAFYKLFEN | |||||||||||||||||||||||||
| 1 | 3emlA | 0.20 | 0.22 | 0.89 | 3.61 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAI-IVGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRS | |||||||||||||||||||
| 2 | 5tgzA | 0.23 | 0.23 | 0.89 | 2.03 | Download | -RGENFMDIECF----MVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRK-DSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVL------------------------PLLGWNCEKLQSVDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARMELAKTLVLILVVLIICWGPLLAIMVYDVFGKMNKLIKTVFAMLCLLNSTVNPIIYALRSKDLRHAFRSM--- | |||||||||||||||||||
| 3 | 5tgzA | 0.19 | 0.23 | 0.88 | 2.13 | Download | ----------GGRGENFMDNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRKD-SRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLG----WNCEKLIFPHID------------------KTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPD-QARMDIELAKTLVLILVVLIICWGPLLAIMVVFGKMNKLIKTVFAFCSMLCLLNPIIYALRSKDLRHAFRSMF-- | |||||||||||||||||||
| 4 | 4djh | 0.16 | 0.20 | 0.92 | 1.55 | Download | -------------------SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRYTKMKTATNIYIFNLALADALVTT-TMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVR---EDVDVIECSLQFPDD---DYSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLDRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSAALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP | |||||||||||||||||||
| 5 | 4yay | 0.18 | 0.21 | 0.93 | 1.26 | Download | LKTTRNAYIQKYLILNSSDCNYIFVMIPTLYSIIFVVGIFGNSLVVIVIYFYMKLKTVASVFLLNLALADLCFLLTLPLWAVYTAMEYRWPFGNYLCKIASASVSFNLYASVFLLTCLSIDRYLAIVHPMKSRLRRTMLVAKVTCIIIWLLAGLASLPAIIHR-NVFF------IITVCAFHYE--------TLPIGLGLTKNILGFLFPFLIILTSYTLIWKALK------KNDDIFKIIMAIVLFFFFSWIPHQIFTFLDLGIDIVDTAMPITICIAYFNNCLNPLFYGFLGKKFKRYFLQLL-- | |||||||||||||||||||
| 6 | 3emlA | 0.20 | 0.22 | 0.89 | 3.76 | Download | ---------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCF-TFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRS | |||||||||||||||||||
| 7 | 4iaq | 0.22 | 0.23 | 0.84 | 1.70 | Download | ---------------------PWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFF-WRQASE----------CVVN----------TDHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIADARERKATKTLG---IILGAFIVCWLIISLVMPIH--L-AIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIR- | |||||||||||||||||||
| 8 | 2z73A | 0.19 | 0.23 | 0.94 | 2.81 | Download | --EYNPSIVVHPHWREFDQVPAVYYSLGIFIGICGIIGCGGNGIVIYLFTKTKSLQTPANMFIINLAFSDFTFSLVNGPLMTISCFLKKWIFGFAACKVYGFIGGIFGFMSIMTMAMISIDRYNVIGRPMAASKKMSHRRAFIMIIFVWLWSVLWAIGPIFGWGAYTLEGV----------------LCSRDSTTRSNILCMFILGFFGPILIIFFCYFNIVMAQAGANAEMRLAKISIVIVSQFLLSWSPYAVVALLAQFGPLEWVTPYAAQLPVMFAKASAIHNPMIYSVSHPKFREAISQTFPW | |||||||||||||||||||
| 9 | 3emlA | 0.20 | 0.22 | 0.89 | 5.33 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS--TGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAII-VGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRS | |||||||||||||||||||
| 10 | 2ydoA | 0.18 | 0.20 | 0.92 | 6.06 | Download | -----------------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSAAAADILVGVLAIPFAIA--ISTGFCAACHGCLFIACFVLVLTASSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQPKEGKAHSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLKQMESTLQKEVHAAKSLAIIVGLFALCWLTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRS | |||||||||||||||||||
| ||||||||||||||||||||||||||
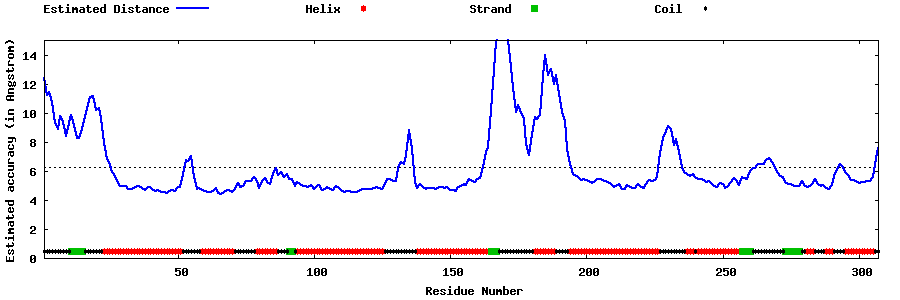
| Generated 3D models | Estimated local accuracy of models | ||
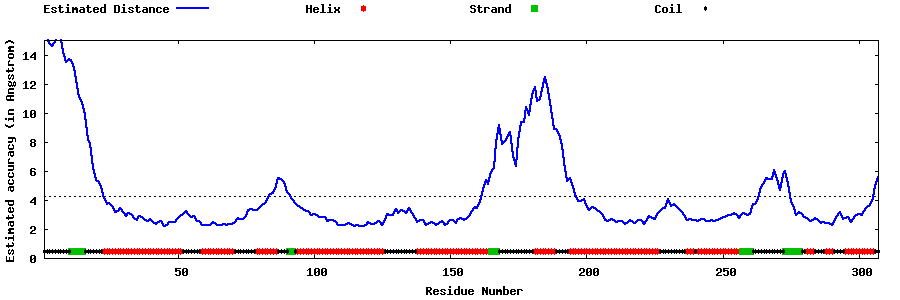 | |||
|
|
|||
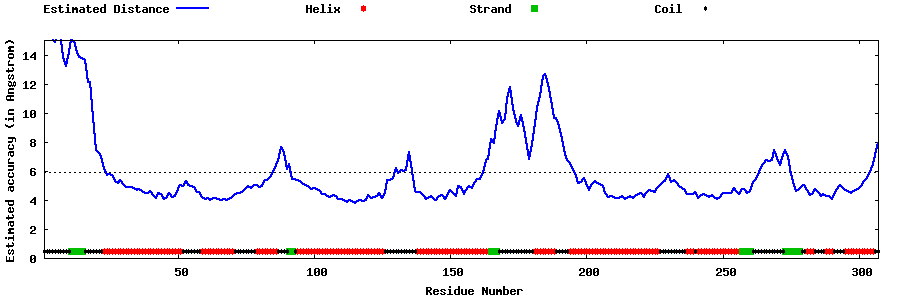 | |||
|
| |||
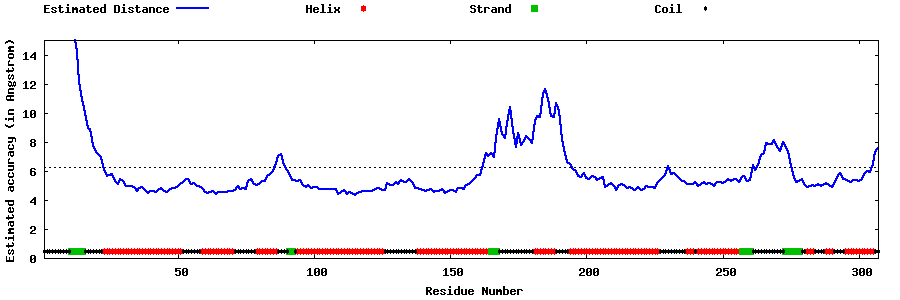 | |||
|
| |||
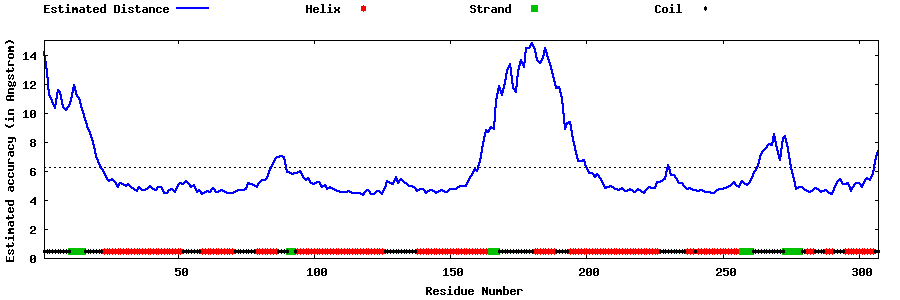 | |||
|
| |||
 | |||
|
| |||
