
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MTLRNSSSVTEFILVGLSEQPELQLPLFLLFLGIYVFTVVGNLGLITLIGINPSLHTPMYFFLFNLSFIDLCYSCVFTPKMLNDFVSESIISYVGCMTQLFFFCFFVNSECYVLVSMAYDRYVAICNPLLYMVTMSPRVCFLLMFGSYVVGFAGAMAHTGSMLRLTFCDSNVIDHYLCDVLPLLQLSCTSTHVSELVFFIVVGVITMLSSISIVISYALILSNILCIPSAEGRSKAFSTWGSHIIAVALFFGSGTFTYLTTSFPGSMNHGRFASVFYTNVVPMLNPSIYSLRNKDDKLALGKTLKRVLF | |
| CCCCCCCCCSSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCCHHHHHHHHHCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCHHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCHHCCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSSCCHHHCCCCHHHCCCCHHHHHHHHHHHHCCCC | |
| 989888423034685589980538999999999999999999899999962888767498998789988347102571889998863684678999999999999999999999999865135206331288026687999999999999999999999998553078999148833581888777046862778889999999999999999999999999980366757675421064889998999985452237478998878788789987211031243574404659899999999841369 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MTLRNSSSVTEFILVGLSEQPELQLPLFLLFLGIYVFTVVGNLGLITLIGINPSLHTPMYFFLFNLSFIDLCYSCVFTPKMLNDFVSESIISYVGCMTQLFFFCFFVNSECYVLVSMAYDRYVAICNPLLYMVTMSPRVCFLLMFGSYVVGFAGAMAHTGSMLRLTFCDSNVIDHYLCDVLPLLQLSCTSTHVSELVFFIVVGVITMLSSISIVISYALILSNILCIPSAEGRSKAFSTWGSHIIAVALFFGSGTFTYLTTSFPGSMNHGRFASVFYTNVVPMLNPSIYSLRNKDDKLALGKTLKRVLF | |
| 856624030010000000432601010023033313212323320020010003000000000100000001000000030013003633021300100110000000000100000000000000211202030023000000210111002003000000010201442201000002210020001313110100011013213303300330331001000103136223101000010210010232012000000335332434100002103200230030000213301400220154347 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCCSSSSSSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCCHHHHHHHHHCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCHHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCHHCCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSSCCHHHCCCCHHHCCCCHHHHHHHHHHHHCCCC MTLRNSSSVTEFILVGLSEQPELQLPLFLLFLGIYVFTVVGNLGLITLIGINPSLHTPMYFFLFNLSFIDLCYSCVFTPKMLNDFVSESIISYVGCMTQLFFFCFFVNSECYVLVSMAYDRYVAICNPLLYMVTMSPRVCFLLMFGSYVVGFAGAMAHTGSMLRLTFCDSNVIDHYLCDVLPLLQLSCTSTHVSELVFFIVVGVITMLSSISIVISYALILSNILCIPSAEGRSKAFSTWGSHIIAVALFFGSGTFTYLTTSFPGSMNHGRFASVFYTNVVPMLNPSIYSLRNKDDKLALGKTLKRVLF | |||||||||||||||||||||||||
| 1 | 3emlA | 0.16 | 0.20 | 0.89 | 3.62 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITISTG-FCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAI-IVGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL | |||||||||||||||||||
| 2 | 5tgzA | 0.21 | 0.25 | 0.89 | 2.00 | Download | -RGENFMDIECF----MVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRKDSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVL------------------------PLLGWNCEKLQSVDKTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDQARMELAKTLVLILVVLIICWGPLLAIMVYDVFGKMNKLIKTVFAMLCLLNSTVNPIIYALRSKDLRHAFRSM------ | |||||||||||||||||||
| 3 | 5tgzA | 0.21 | 0.25 | 0.88 | 2.08 | Download | ---GGRGENFMDIECFMVLNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHSRSLRCPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRKDSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLG----WNCEKLIFPHID------------------KTYLMFWIGVVSVLLLFIVYAYMYILWKAHSHAPDELAKTLVLILVVLIICWGPLLAIMVYDVFGKMNK------LIKTVFLCLLNSTVNPIIYALRSKDLRHAFRSMF----- | |||||||||||||||||||
| 4 | 4djh | 0.13 | 0.23 | 0.91 | 1.54 | Download | -------------------SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRYTKMKTATNIYIFNLALADALVTT-TMPFQSTVYLMNWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVR---EDVDVIECSLQFPDD---DYSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSAALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP--- | |||||||||||||||||||
| 5 | 4yay | 0.15 | 0.25 | 0.91 | 1.25 | Download | KTTR-NAYIQKYLILNSSDCNYIFVMIPTLYSIIFVVGIFGNSLVVIVIYFYMKLKTVASVFLLNLALADLCFLLTLPLWAVYTAMEYWPFGNYLCKIASASVSFNLYASVFLLTCLSIDRYLAIVHPMKSRLRRTMLVAKVTCIIIWLLAGLASLPAIIH-RNVFF------IITVCAFHYE--------TLPIGLGLTKNILGFLFPFLIILTSYTLIWKALK------KNDDIFKIIMAIVLFFFFSWIPHQIFTFLDLGIDIVDTAMPITICIAYFNNCLNPLFYGFLGKKFKRYFLQLL----- | |||||||||||||||||||
| 6 | 3emlA | 0.16 | 0.20 | 0.89 | 3.74 | Download | ---------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT-ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCF-TFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL | |||||||||||||||||||
| 7 | 4iaq | 0.19 | 0.22 | 0.84 | 1.71 | Download | --------------------LPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFFW-RQASECVVN--------------------TDHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIADARERKATKTLG---IILGAFIVCWFIISLVMPIH--L-AIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK-- | |||||||||||||||||||
| 8 | 2z73A | 0.17 | 0.22 | 0.97 | 2.45 | Download | TWWYNPSIVVHPHWREFDQVPAVYYSLGIFIGICGIIGCGGNGIVIYLFTKTKSLQTPANMFIINLAFSDFTFSLVNGPLMTISCFLKKIFGFAACKVYGFIGGIFGFMSIMTMAMISIDRYNVIGRPMAASKKMSHRRAFIMIIFVWLWSVLWAIGPIFGWGAYTLEGVLCNCSFDY---------ISRDSTTRSNILCMFILGFFGPILIIFFCYFNIVMAQAGANAEMRLAKISIVIVSQFLLSWSPYAVVALLAQFGPLEWVTPYAAQLPVMFAKASAIHNPMIYSVSHPKFREAISQTFPWVLT | |||||||||||||||||||
| 9 | 3emlA | 0.16 | 0.20 | 0.89 | 5.20 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS--GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAI-IVGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL | |||||||||||||||||||
| 10 | 2ydoA | 0.14 | 0.18 | 0.92 | 5.95 | Download | -----------------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSAAAADILVGVLAIPFAIA-ISTGFCAACHGCLFIACFVLVLTASSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQPKEGKAHSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLKQMESTLQKEVHAAKSLAIIVGLFALCWLTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL | |||||||||||||||||||
| ||||||||||||||||||||||||||
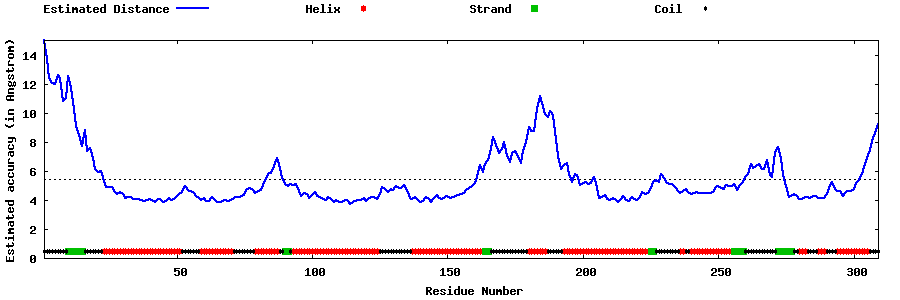
| Generated 3D models | Estimated local accuracy of models | ||
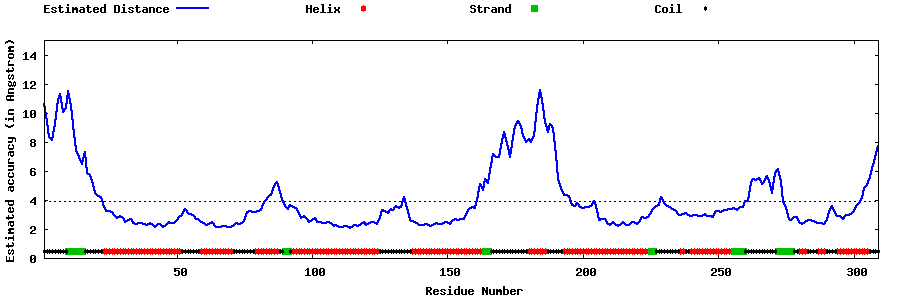 | |||
|
|
|||
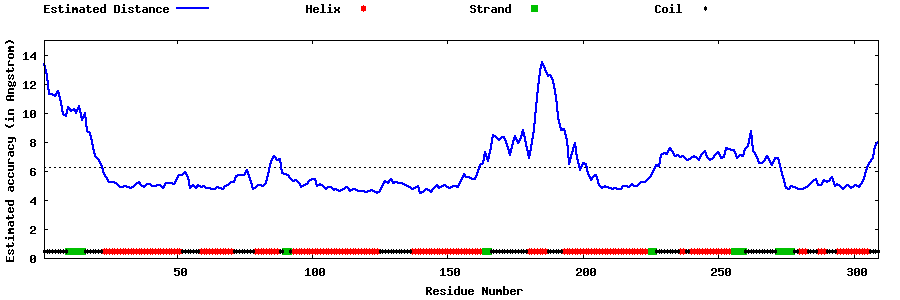 | |||
|
| |||
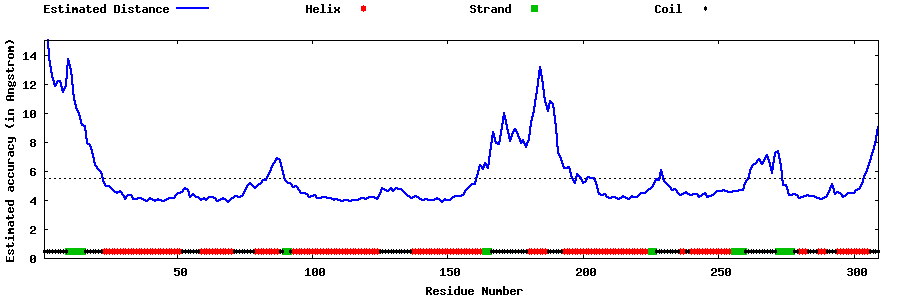 | |||
|
| |||
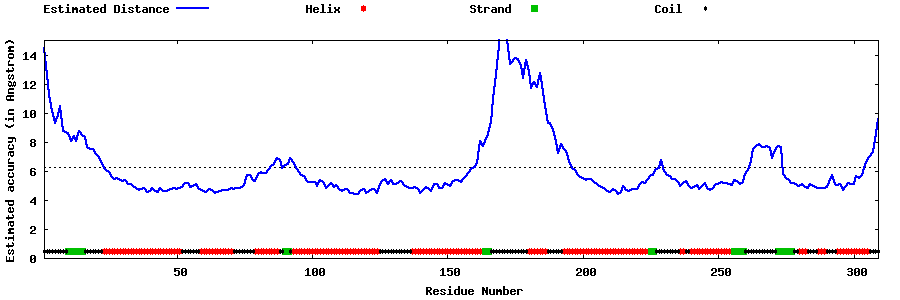 | |||
|
| |||
 | |||
|
| |||
