GPCR-I-TASSER results for P35414
[Click on P35414_results.tar.bz2 to download the tarball file including all modeling results listed on this page]
| Submitted Sequence |
| >P35414 MEEGGDFDNYYGADNQSECEYTDWKSSGALIPAIYMLVFLLGTTGNGLVLWTVFRSSREK RRSADIFIASLAVADLTFVVTLPLWATYTYRDYDWPFGTFFCKLSSYLIFVNMYASVFCL TGLSFDRYLAIVRPVANARLRLRVSGAVATAVLWVLAALLAMPVMVLRTTGDLENTTKVQ CYMDYSMVATVSSEWAWEVGLGVSSTTVGFVVPFTIMLTCYFFIAQTIAGHFRKERIEGL RKRRRLLSIIVVLVVTFALCWMPYHLVKTLYMLGSLLHWPCDFDLFLMNIFPYCTCISYV NSCLNPFLYAFFDPRFRQACTSMLCCGQSRCAGTSHSSSGEKSASYSSGHSQGPGPNMGK GGEQMHEKSIPYSQETLVVD |
| Predicted Secondary Structure |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 | | | | | | | | | | | | | | | | | | | MEEGGDFDNYYGADNQSECEYTDWKSSGALIPAIYMLVFLLGTTGNGLVLWTVFRSSREKRRSADIFIASLAVADLTFVVTLPLWATYTYRDYDWPFGTFFCKLSSYLIFVNMYASVFCLTGLSFDRYLAIVRPVANARLRLRVSGAVATAVLWVLAALLAMPVMVLRTTGDLENTTKVQCYMDYSMVATVSSEWAWEVGLGVSSTTVGFVVPFTIMLTCYFFIAQTIAGHFRKERIEGLRKRRRLLSIIVVLVVTFALCWMPYHLVKTLYMLGSLLHWPCDFDLFLMNIFPYCTCISYVNSCLNPFLYAFFDPRFRQACTSMLCCGQSRCAGTSHSSSGEKSASYSSGHSQGPGPNMGKGGEQMHEKSIPYSQETLVVD | |
| CCCCCCCCCCCCCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHCCCHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHSSSSCCCCCSSSSSCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCHHHHHHHHHHHCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC | |
| 99999888777888888786765218798999999999999847399857989866887876999999999999999999719999999768998588758989999999999999999999999847888751523446550457666799999999999999998543670799758883668865465327799999999999999999999999999999999813356664201211458999999999999999579999999999998747990699999999999999999999998999996198999999998453146887767787777777767899999998888887677889999987673779 |
| Predicted Solvent Accessibility |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 | | | | | | | | | | | | | | | | | | | MEEGGDFDNYYGADNQSECEYTDWKSSGALIPAIYMLVFLLGTTGNGLVLWTVFRSSREKRRSADIFIASLAVADLTFVVTLPLWATYTYRDYDWPFGTFFCKLSSYLIFVNMYASVFCLTGLSFDRYLAIVRPVANARLRLRVSGAVATAVLWVLAALLAMPVMVLRTTGDLENTTKVQCYMDYSMVATVSSEWAWEVGLGVSSTTVGFVVPFTIMLTCYFFIAQTIAGHFRKERIEGLRKRRRLLSIIVVLVVTFALCWMPYHLVKTLYMLGSLLHWPCDFDLFLMNIFPYCTCISYVNSCLNPFLYAFFDPRFRQACTSMLCCGQSRCAGTSHSSSGEKSASYSSGHSQGPGPNMGKGGEQMHEKSIPYSQETLVVD | |
| 72464324222334242404334240010000221120023023011000000002334321000000012000210110013010000002442001100110011112210101130100000000000010020232232110000000001000000000000020242764310100020133333433210100010111121133101102310010001013234544464344210000000000001103103100010010013023341312200100100020200010004253101003610410130032235343444444444434444344344444444444543456433336423248 | |
| Values range from 0 (buried residue) to 9 (highly exposed residue) | |
| Predicted normalized B-factor |

| Top 10 templates used by GPCR-I-TASSER |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 | | | | | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCCCCCCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHCCCHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHSSSSCCCCCSSSSSCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCHHHHHHHHHHHCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC MEEGGDFDNYYGADNQSECEYTDWKSSGALIPAIYMLVFLLGTTGNGLVLWTVFRSSREKRRSADIFIASLAVADLTFVVTLPLWATYTYRDYDWPFGTFFCKLSSYLIFVNMYASVFCLTGLSFDRYLAIVRPVANARLRLRVSGAVATAVLWVLAALLAMPVMVLRTTGDLENTTKVQCYMDYSMVATVSSEWAWEVGLGVSSTTVGFVVPFTIMLTCYFFIAQTIAGHFRKERIEGLRKRRRLLSIIVVLVVTFALCWMPYHLVKTLYMLGSLLHWPCDFDLFLMNIFPYCTCISYVNSCLNPFLYAFFDPRFRQACTSMLCCGQSRCAGTSHSSSGEKSASYSSGHSQGPGPNMGKGGEQMHEKSIPYSQETLVVD | |||||||||||||||||||||||||
| 1 | 4n6hA | 0.28 | 0.25 | 0.79 | 4.14 | Download | ---------------SPGARSASSLALAIAITALYSAVCAVGLLGNVLVMFGIVRY-TKMKTATNIYIFNLALADALATSTLPFQSAKYLME-TWPFGELLCKAVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPAKAKLINICIWVLASGVGVPIMVMAVTRPRDG--AVVCMLQFPSP-----SWYWDTVTKICVFLFAFVVPILIITVCYGLMLLRLRSVRLSGSKEKDRSLRRITRMVLVVVGAFVVCWAPIHIFVIVWTLVD----IDRRDPLVVAALHLCIALGYANSSLNPVLYAFLDENFKRCFRQLCRKPCG--------------------------------------------------- | |||||||||||||||||||
| 2 | 4n6hA | 0.28 | 0.25 | 0.79 | 3.38 | Download | ----------------SPGARASSLALAIAITALYSAVCAVGLLGNVLVMFGIVRY-TKMKTATNIYIFNLALADALATSTLPFQSAKYLME-TWPFGELLCKAVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPAKAKLINICIWVLASGVGVPIMVMAVTRPRDG--AVVCMLQFP-----SPSWYWDTVTKICVFLFAFVVPILIITVCYGLMLLRLRSVLLSGSKEKDRSLRRITRMVLVVVGAFVVCWAPIHIFVIVWTLVDIDRRD----PLVVAALHLCIALGYANSSLNPVLYAFLDENFKRCFRQLCRKPCG--------------------------------------------------- | |||||||||||||||||||
| 3 | 3vw7A | 0.22 | 0.24 | 0.76 | 2.60 | Download | ----------------DASGYLTSSWLTLFVPSVYTGVFVVSLPLNIMAIVVFILK-MKVKKPAVVYMLHLATADVLFVSVLPFKISYYFSGSDWQFGSELCRFVTAAFYCNMYASILLMTVISIDRFLAVVYPM-----RTLGRASFTCLAIWALAIAGVVPLLLKEQTIQVPGLGITTCHDVLSETL----LEGYYAYYFSAFSAVFFFVPLIISTVCYVSIIRCLSSSANIFEYANRSKKSRALFLSAAVFCIFIICFGPTNVLLIAHYSFLSH---TSTTEAAYFAYLLCVCVSSISCCIDPLIYYYASSEC---------------------------------------------------------------- | |||||||||||||||||||
| 4 | 4buoA | 0.25 | 0.22 | 0.77 | 1.92 | Download | ---------------NSDLDVNTDIYSKVLVTAIYLALFVVGTVGNSVTLFTLARK-KS---TVDYYLGSLALSDLLILLAMPVELYNFIVHHPWAFGDAGCRGYYFLRDACTYATALNVVSLSVELYLAICHPFKAKTLMSRSRTKKFISAIWLASALLAIPMLFTMGLQNLSHPGGLVCTP-IVD-------TATLKVVIQVNTFMSFLFPMLVASILNTVIANKLTVMV----PGRVQALRRGVLVLRAVVIAFVVCWLPYHVRRLMFCYISDEQWTTFLFDFYHYFYMLTNALVYVSAAINPILYNLVSANFRQVFLSTL-------------------------------------------------------- | |||||||||||||||||||
| 5 | 4n6hA | 0.28 | 0.25 | 0.79 | 3.70 | Download | -----------------GARSASSLALAIAITALYSAVCAVGLLGNVLVMFGIVRY-TKMKTATNIYIFNLALADALATSTLPFQSAKYLME-TWPFGELLCKAVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPAKAKLINICIWVLASGVGVPIMVMAVTRPRDG--AVVCMLQFPSP-----SWYWDTVTKICVFLFAFVVPILIITVCYGLMLLRLRSVLLSGSKEKDRSLRRITRMVLVVVGAFVVCWAPIHIFVIVWTLVDIDRRD----PLVVAALHLCIALGYANSSLNPVLYAFLDENFKRCFRQLCRKPCG--------------------------------------------------- | |||||||||||||||||||
| 6 | 4pxzA | 0.24 | 0.20 | 0.75 | 2.86 | Download | -----------------SLCTRDYKITQVLFPLLYTVLFFVGLITNGLAMRIFFQ-IRS-KSNFIIFLKNTVISDLLMILTFPFKILSDAKLGTGPLRTFVCQVTSVIFYFTMYISISFLGLITIDRYQKTTRP-----PKNLLGAKILSVVIWAFMFLLSLPNMILTNRQPR-DKNVKKCSFLKSEFGL-----V-WHEIVNYICQVIFWINFLIVIVCYTLITKELYRSYVRTADLGKVPRKKVNVKVFIIIAVFFICFVPFHFARIPYTLSQTRDFDCTAENTLFYVKESTLWLTSLNACLNPFIYFFLCKSF---------------------------------------------------------------- | |||||||||||||||||||
| 7 | 4mbsA | 0.27 | 0.22 | 0.76 | 4.83 | Download | -----------------PCQKINVQIAARLLPPLYSLVFIFGFVGNMLVILILINY-KRLKSMTDIYLLNLAISDLFFLLTVPFWAHYAAA--QWDFGNTMCQLLTGLYFIGFFSGIFFIILLTIDRYLAVVHAVFALKARTVTFGVVTSVITWVVAVFASLPNIIFTRSQKEGL--HYTCSSHFPYSQ----YQFWKNFQTLKIVILGLVLPLLVMVICYSGILKTLLRE---------KKRHRDVRLIFTIMIVYFLFWAPYNIVLLLNTFEFFGLNNCSSSNRLDQAMQVTETLGMTHCCINPIIYAFVGEEFRNYLLVFFQ------------------------------------------------------- | |||||||||||||||||||
| 8 | 4mbsA | 0.27 | 0.22 | 0.77 | 3.80 | Download | -----------------PCQKINVQIAARLLPPLYSLVFIFGFVGNMLVILILINY-KRLKSMTDIYLLNLAISDLFFLLTVPFWAHYAA--AQWDFGNTMCQLLTGLYFIGFFSGIFFIILLTIDRYLAVVHAVFALKARTVTFGVVTSVITWVVAVFASLPNIIFTRSQK--EGLHYTCSSHFPYSQ----YQFWKNFQTLKIVILGLVLPLLVMVICYSGILKTLLRMKEEE-----KKRHRDVRLIFTIMIVYFLFWAPYNIVLLLNTFQEFGLNNCSSSNRLDQAMQVTETLGMTHCCINPIIYAFVGEEFRNYLLVFFQ------------------------------------------------------- | |||||||||||||||||||
| 9 | 4mbsA | 0.26 | 0.22 | 0.78 | 4.43 | Download | PCQKIN----------------VKQIAARLLPPLYSLVFIFGFVGNMLVILILINYKR-LKSMTDIYLLNLAISDLFFLLTVPFWAHYAA--AQWDFGNTMCQLLTGLYFIGFFSGIFFIILLTIDRYLAVVHAVFALKARTVTFGVVTSVITWVVAVFASLPNIIFTRSQKEGL--HYTCSSHFPYSQ----YQFWKNFQTLKIVILGLVLPLLVMVICYSGILKTLLRMKEEE-----KKRHRDVRLIFTIMIVYFLFWAPYNIVLLLNTFQEFGLNNCSSSNRLDQAMQVTETLGMTHCCINPIIYAFVGEEFRNYLLVFF-------------------------------------------------------Q | |||||||||||||||||||
| 10 | 4n6hA | 0.27 | 0.26 | 0.82 | 10.90 | Download | -LKTTRNAYIQKYLGSPGARSASSLALAIAITALYSAVCAVGLLGNVLVMFGIVRY-TKMKTATNIYIFNLALADALATSTLPFQSAKYLME-TWPFGELLCKAVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPAKAKLINICIWVLASGVGVPIMVMAVTRPRD--GAVVCMLQFPSPSWY-----WDTVTKICVFLFAFVVPILIITVCYGLMLLRLRSVRLSGSKEKDRSLRRITRMVLVVVGAFVVCWAPIHIFVIVWTLVD----IDRRDPLVVAALHLCIALGYANSSLNPVLYAFLDENFKRCFRQLC-------------------------------------------------------- | |||||||||||||||||||
| ||||||||||||||||||||||||||
| Top 5 Models predicted by GPCR-I-TASSER |
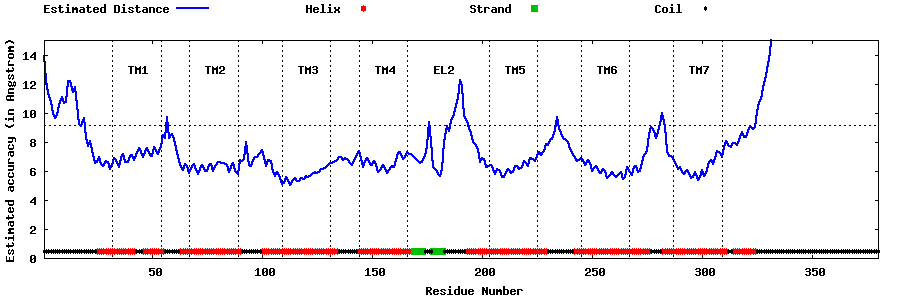
| Generated 3D models | Estimated local accuracy of models | ||
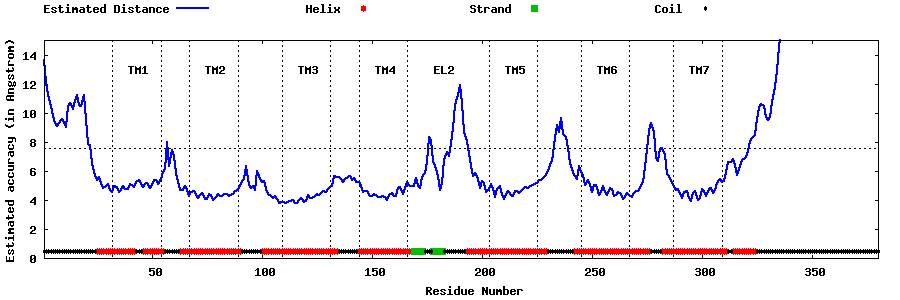 | |||
|
|
|||
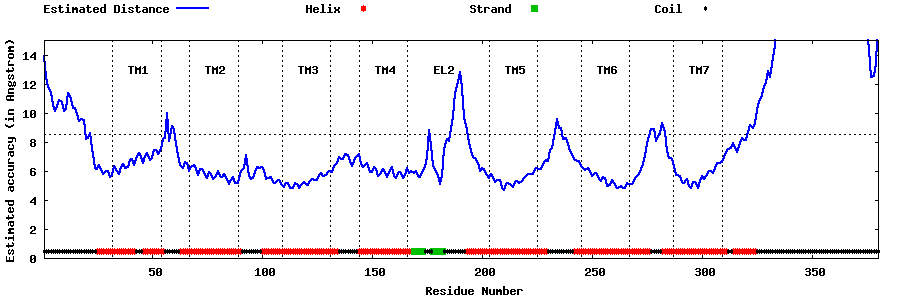 | |||
|
| |||
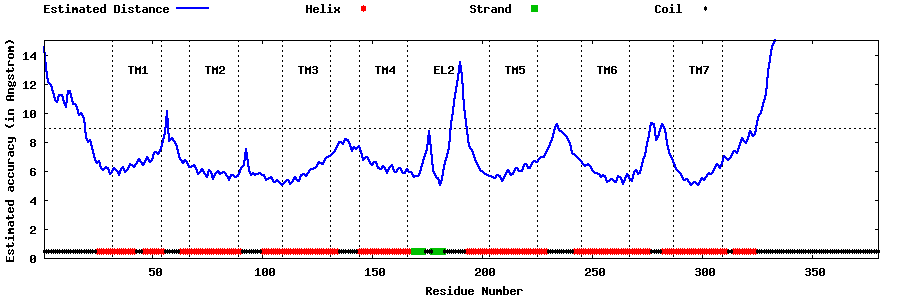 | |||
|
| |||
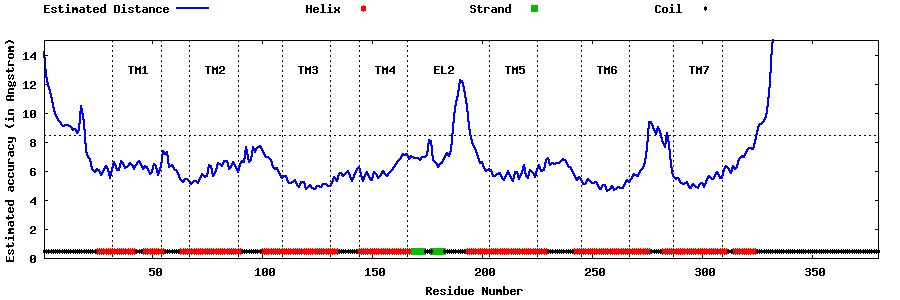 | |||
|
| |||
 | |||
|
| |||
| Please cite following articles when you use the GPCR-I-TASSER server: | |
| J Zhang, J Yang, R Jang, Y Zhang. Hybrid structure modeling of G protein-coupled receptors in the human genome, submitted (2015). |