GPCR-I-TASSER results for P58181
[Click on P58181_results.tar.bz2 to download the tarball file including all modeling results listed on this page]
| Submitted Sequence |
| >P58181 MKRQNQSCVVEFILLGFSNFPELQVQLFGVFLVIYVVTLMGNAIITVIISLNQSLHVPMY LFLLNLSVVEVSFSAVITPEMLVVLSTEKTMISFVGCFAQMYFILLFGGTECFLLGAMAY DRFAAICHPLNYPVIMNRGVFMKLVIFSWISGIMVATVQTTWVFSFPFCGPNEINHLFCE TPPVLELVCADTFLFEIYAFTGTILIVMVPFLLILLSYIRVLFAILKMPSTTGRQKAFST CASHLTSVTLFYGTANMTYLQPKSGYSPETKKLISLAYTLLTPLLNPLIYSLRNSEMKRT LIKLWRRKVILHTF |
| Predicted Secondary Structure |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MKRQNQSCVVEFILLGFSNFPELQVQLFGVFLVIYVVTLMGNAIITVIISLNQSLHVPMYLFLLNLSVVEVSFSAVITPEMLVVLSTEKTMISFVGCFAQMYFILLFGGTECFLLGAMAYDRFAAICHPLNYPVIMNRGVFMKLVIFSWISGIMVATVQTTWVFSFPFCGPNEINHLFCETPPVLELVCADTFLFEIYAFTGTILIVMVPFLLILLSYIRVLFAILKMPSTTGRQKAFSTCASHLTSVTLFYGTANMTYLQPKSGYSPETKKLISLAYTLLTPLLNPLIYSLRNSEMKRTLIKLWRRKVILHTF | |
| CCCCCCCSSSSSSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHCCCHHHHHHHHCCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCCCCHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHCCCHHHHHHHHHHHHHCHSSSSSCCCCCCCCCCCCSSSSSHHHHHHCCCCHHHCCCCHHHHHHHHHHHHHHHHHCCC | |
| 99988723556567668998526999999999999999998899989887288766748999888999977787028799999862699588589999999999999999999999998650564065444783157869999999999999999999999981427899896789734808888784148639999999999999999799999999999999803867477664102758689969998620315882689999887884998746326642024543036499999999999765533069 |
| Predicted Solvent Accessibility |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MKRQNQSCVVEFILLGFSNFPELQVQLFGVFLVIYVVTLMGNAIITVIISLNQSLHVPMYLFLLNLSVVEVSFSAVITPEMLVVLSTEKTMISFVGCFAQMYFILLFGGTECFLLGAMAYDRFAAICHPLNYPVIMNRGVFMKLVIFSWISGIMVATVQTTWVFSFPFCGPNEINHLFCETPPVLELVCADTFLFEIYAFTGTILIVMVPFLLILLSYIRVLFAILKMPSTTGRQKAFSTCASHLTSVTLFYGTANMTYLQPKSGYSPETKKLISLAYTLLTPLLNPLIYSLRNSEMKRTLIKLWRRKVILHTF | |
| 87561303001000000043240101001302331331233332002001002300000010020001101101003203000101164320101002001100000021001000100000000002002000300330000001100210131031101100102003524010000032000200021031102211231233133123002302320010001031463231000000001000001120010000103163344341000021033203310300001042014002200322212434 | |
| Values range from 0 (buried residue) to 9 (highly exposed residue) | |
| Predicted normalized B-factor |

| Top 10 templates used by GPCR-I-TASSER |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCSSSSSSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHCCCHHHHHHHHCCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCCCCHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHCCCHHHHHHHHHHHHHCHSSSSSCCCCCCCCCCCCSSSSSHHHHHHCCCCHHHCCCCHHHHHHHHHHHHHHHHHCCC MKRQNQSCVVEFILLGFSNFPELQVQLFGVFLVIYVVTLMGNAIITVIISLNQSLHVPMYLFLLNLSVVEVSFSAVITPEMLVVLSTEKTMISFVGCFAQMYFILLFGGTECFLLGAMAYDRFAAICHPLNYPVIMNRGVFMKLVIFSWISGIMVATVQTTWVFSFPFCGPNEINHLFCETPPVLELVCADTFLFEIYAFTGTILIVMVPFLLILLSYIRVLFAILKMPSTTGRQKAFSTCASHLTSVTLFYGTANMTYLQPKSGYSPETKKLISLAYTLLTPLLNPLIYSLRNSEMKRTLIKLWRRKVILHTF | |||||||||||||||||||||||||
| 1 | 4iaqA | 0.18 | 0.21 | 0.85 | 2.25 | Download | ------------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISL---------PPCVVNTDH---------------------ILYTVYSTVGAYFPTLLLIALYGRIYVEARSRIIQKYAARERKATKTLGIILGAFIVCWLPFFIISLVMPIHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK------ | |||||||||||||||||||
| 2 | 3emlA | 0.21 | 0.22 | 0.88 | 3.62 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINC-FTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ-- | |||||||||||||||||||
| 3 | 3uonA | 0.17 | 0.23 | 0.88 | 2.55 | Download | --------------------TFEVVFIVLVAGSLSLVTIIGNILVMVSIKVNRHLQTVNNYFLFSLACADLIIGVFSMNLYTLYTVIGYWPLGPVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPVKRTTKMAGMMIAAAWVLSFILWAPAILFWQFIV--GVRTVEDGECYIQFF------S---NAAVTFGTAIAAFYLPVIIMTVLYWHISRASKSRINISREKKVTRTILAILLAFIITWAPYNVMVLINTFCCIPNTVWTIGYWLCYINSTINPACYALCNATFKKTFKHLLM-------- | |||||||||||||||||||
| 4 | 4bvnA | 0.16 | 0.18 | 0.87 | 2.07 | Download | ------------------LSQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASVETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMM----HWWRDEDPQALKCYQD----PGCCDFVTNRAYAIASSIISFYIPLLIMIFVALRVYREAKE-----REHKALKTLGIIMGVFTLCWLPFFLVNIVNVFNLVPKWLFVAFNWLGYANSAMNPIILC-RSPDFRKAFKRLLA-------- | |||||||||||||||||||
| 5 | 3emlA | 0.21 | 0.22 | 0.88 | 4.07 | Download | ---------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCF-TFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ-- | |||||||||||||||||||
| 6 | 4bvnA | 0.16 | 0.18 | 0.88 | 2.97 | Download | ------------------LSQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASVETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMMHWWR----DEDPQALKCYQD----PGCCDFVTNRAYAIASSIISFYIPLLIMIFVALRVYREAKEQ---MREHKALKTLGIIMGVFTLCWLPFFLVNIVNVFDLVPKWLFVAFNWLGYANSAMNPIILC-RSPDFRKAFKRLLA-------- | |||||||||||||||||||
| 7 | 2z73A | 0.18 | 0.21 | 0.94 | 2.62 | Download | ---ENPSIVVHPHWREFDQVPAVYYSLGIFIGICGIIGCGGNGIVIYLFTKTKSLQTPANMFIINLAFSDFTFSLVNGPLMTISCFLKKWIFGFAACKVYGFIGGIFGFMSIMTMAMISIDRYNVIGRPMAASKKMSHRRAFIMIIFVWLWSVLWAIGPIFGTLEGVLCNDYI----------------SRDSTTRSNILCMFILGFFGPILIIFFCYFNIVMAQAGANAEMRLAKISIVIVSQFLLSWSPYAVVALLAQFGPLEWVTPYAAQLPVMFAKASAIHNPMIYSVSHPKFREAISQTFPWVLTCCQF | |||||||||||||||||||
| 8 | 3emlA | 0.20 | 0.22 | 0.89 | 5.25 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS--TGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAI-IVGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ-- | |||||||||||||||||||
| 9 | 3emlA | 0.21 | 0.22 | 0.89 | 5.58 | Download | I--------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLV-----------PLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALC-WLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ-- | |||||||||||||||||||
| 10 | 3emlA | 0.20 | 0.22 | 0.83 | 3.20 | Download | ---------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS--TGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQSQGCGEGQVACLFEDV--------VPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQ-----LVHAAKSCWLPLHIINCFTFFCPD------CSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKI---------- | |||||||||||||||||||
| ||||||||||||||||||||||||||
| Top 5 Models predicted by GPCR-I-TASSER |
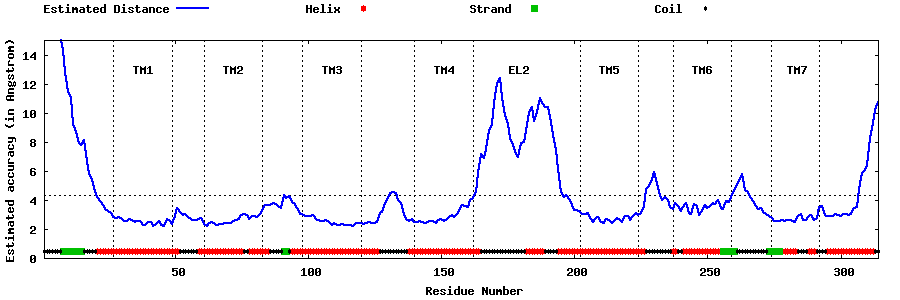
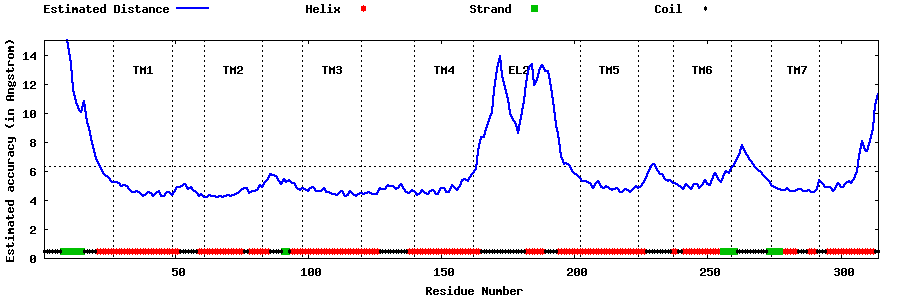
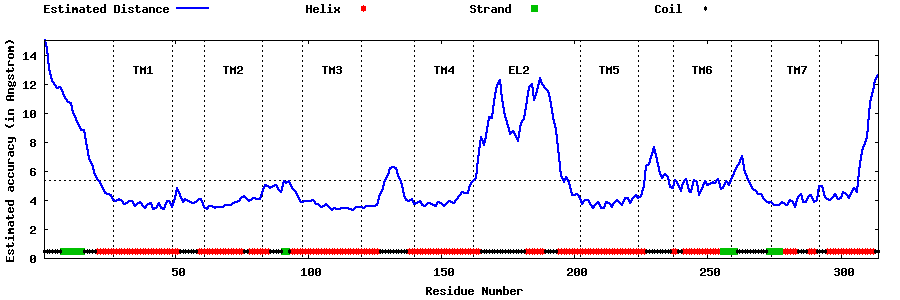
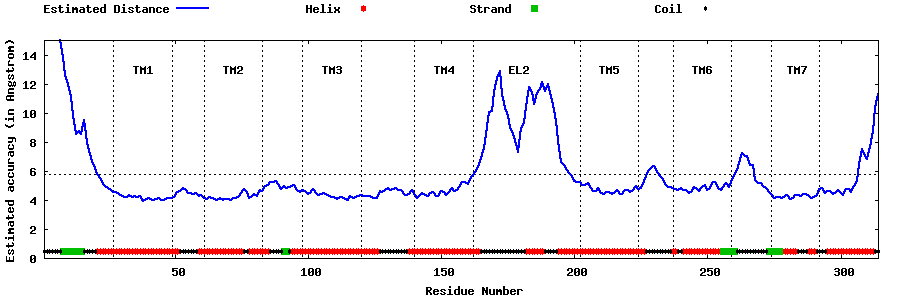
| Generated 3D models | Estimated local accuracy of models | ||
 | |||
|
|
|||
 | |||
|
| |||
 | |||
|
| |||
 | |||
|
| |||
 | |||
|
| |||
| Please cite following articles when you use the GPCR-I-TASSER server: | |
| J Zhang, J Yang, R Jang, Y Zhang. Hybrid structure modeling of G protein-coupled receptors in the human genome, submitted (2015). |