GPCR-I-TASSER results for Q01718
[Click on Q01718_results.tar.bz2 to download the tarball file including all modeling results listed on this page]
| Submitted Sequence |
| >Q01718 MKHIINSYENINNTARNNSDCPRVVLPEEIFFTISIVGVLENLIVLLAVFKNKNLQAPMY FFICSLAISDMLGSLYKILENILIILRNMGYLKPRGSFETTADDIIDSLFVLSLLGSIFS LSVIAADRYITIFHALRYHSIVTMRRTVVVLTVIWTFCTGTGITMVIFSHHVPTVITFTS LFPLMLVFILCLYVHMFLLARSHTRKISTLPRANMKGAITLTILLGVFIFCWAPFVLHVL LMTFCPSNPYCACYMSLFQVNGMLIMCNAVIDPFIYAFRSPELRDAFKKMIFCSRYW |
| Predicted Secondary Structure |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 | | | | | | | | | | | | | | MKHIINSYENINNTARNNSDCPRVVLPEEIFFTISIVGVLENLIVLLAVFKNKNLQAPMYFFICSLAISDMLGSLYKILENILIILRNMGYLKPRGSFETTADDIIDSLFVLSLLGSIFSLSVIAADRYITIFHALRYHSIVTMRRTVVVLTVIWTFCTGTGITMVIFSHHVPTVITFTSLFPLMLVFILCLYVHMFLLARSHTRKISTLPRANMKGAITLTILLGVFIFCWAPFVLHVLLMTFCPSNPYCACYMSLFQVNGMLIMCNAVIDPFIYAFRSPELRDAFKKMIFCSRYW | |
| CCCCCCCCCCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHCSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCHHHHHHHHHHHHSSSSSHHHHHHHHHHHHHHHHCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHCCHHHHHHHHHHHCCCCCC | |
| 986303888988887889996289999999999999999999985432033799997899999999999999999999999999997146514662087789999999999999999999999999839994053777767669999999999999999999999998636657314579999999999999999999999999998650216576997847136652447689999999999869876633179999999999998998829999818999999999996777889 |
| Predicted Solvent Accessibility |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 | | | | | | | | | | | | | | MKHIINSYENINNTARNNSDCPRVVLPEEIFFTISIVGVLENLIVLLAVFKNKNLQAPMYFFICSLAISDMLGSLYKILENILIILRNMGYLKPRGSFETTADDIIDSLFVLSLLGSIFSLSVIAADRYITIFHALRYHSIVTMRRTVVVLTVIWTFCTGTGITMVIFSHHVPTVITFTSLFPLMLVFILCLYVHMFLLARSHTRKISTLPRANMKGAITLTILLGVFIFCWAPFVLHVLLMTFCPSNPYCACYMSLFQVNGMLIMCNAVIDPFIYAFRSPELRDAFKKMIFCSRYW | |
| 654333324121333364441220201222232112201312201110203143011000000001000100002111321001002323312230100200010100011000000001100201310101020020333123300000000010000010100000233010000023323321200010113000101320443453444412000000000000100112110000000003333223022001110112012010010210000165215031200102323 | |
| Values range from 0 (buried residue) to 9 (highly exposed residue) | |
| Predicted normalized B-factor |

| Top 10 templates used by GPCR-I-TASSER |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCCCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHCSCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCHHHHHHHHHHHHSSSSSHHHHHHHHHHHHHHHHCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHCCHHHHHHHHHHHCCCCCC MKHIINSYENINNTARNNSDCPRVVLPEEIFFTISIVGVLENLIVLLAVFKNKNLQAPMYFFICSLAISDMLGSLYKILENILIILRNMGYLKPRGSFETTADDIIDSLFVLSLLGSIFSLSVIAADRYITIFHALRYHSIVTMRRTVVVLTVIWTFCTGTGITMVIFSHHVPTVITFTSLFPLMLVFILCLYVHMFLLARSHTRKISTLPRANMKGAITLTILLGVFIFCWAPFVLHVLLMTFCPSNPYCACYMSLFQVNGMLIMCNAVIDPFIYAFRSPELRDAFKKMIFCSRYW | |||||||||||||||||||||||||
| 1 | 2rh1A | 0.25 | 0.26 | 0.85 | 3.97 | Download | ----------------------WVVGMGIVMSLIVLAIVFGNVLVITAIAKFERLQTVTNYFITSLACADLVMGLAVVPFGAAHILMK------MWTFGNFWCEFWTSIDVLCVTASIETLCVIAVDRYFAITSPFKYQSLLTKNKARVIILMVWIVSGLTSFLPIQMTNQAYAIASSIVSFYVPLVIMVFVYSRVFQEAKRQ-------LLKEHKALKTLGIIMGTFTLCWLPFFIVNIVHVIQDN----LIRKEVYILLNWIGYVNSGFNPLIYCR-SPDFRIAFQELLC----- | |||||||||||||||||||
| 2 | 4iaqA | 0.27 | 0.25 | 0.90 | 3.38 | Download | ------------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTG------RWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFFWRHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIQKYLLMAARERKATKTLGIILGAFIVCWLPFFIISLVMPI---------HLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK--- | |||||||||||||||||||
| 3 | 4iaqA | 0.27 | 0.25 | 0.90 | 3.20 | Download | ------------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTG------RWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFFWRHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIQKYLLMAARERKATKTLGIILGAFIVCWLPFFIISLVMPIH---------LAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK--- | |||||||||||||||||||
| 4 | 4iarA | 0.26 | 0.26 | 0.91 | 2.58 | Download | ------------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTV------TGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFFWRQILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIADLEYLAARERKATKTLGIILGAFIVCWLPFFIISLVMPI-------WFHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK--- | |||||||||||||||||||
| 5 | 4iarA | 0.26 | 0.26 | 0.91 | 2.04 | Download | ----------Y--IYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTG------RWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFFWRQILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIADLEYLAARERKATKTLGIILGAFIVCWLPFFIISLVMPI-------WFHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK--- | |||||||||||||||||||
| 6 | 4iaqA | 0.27 | 0.25 | 0.89 | 3.39 | Download | ----------------DSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTG------RWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFFWRQILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIQKYLLMAARERKATKTLGIILGAFIVCWLPFFIISLVMPI---------HLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK--- | |||||||||||||||||||
| 7 | 4iarA | 0.27 | 0.26 | 0.90 | 2.93 | Download | -------------YIYQSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTG------RWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFFWRQA--TVYSTVGAFYFPTLLLIALYGRIYVEARSRIADLEYLAARERKATKTLGIILGAFIVCWLPFFIISLVMPI-------WFHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK--- | |||||||||||||||||||
| 8 | 4buoA | 0.17 | 0.24 | 0.91 | 2.38 | Download | -----------NSDLDVNTDIYSKVLVTAIYLALFVVGTVGNSVTLFTLARKKSLQSTVDYYLGSLALSDLLILLLAMPVELYNFIWVHH----PWAFGDAGCRGYYFLRDACTYATALNVVSLSVELYLAICHPFKAKTLMSRSRTKKFISAIWLASALLAIPVDTATLKVVIQVNTFMSFLFPMLVASILNTVIANKLTVMVHQALRRGVLVLRAVVIAF------VVCWLPYHVRRLMFCYISDEQWTDFYHYFYMLTNALVYVSAAINPILYNLVSANFRQVFLSTL------ | |||||||||||||||||||
| 9 | 4iaqA | 0.27 | 0.25 | 0.90 | 3.44 | Download | ------------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGR------WTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPPFFWRHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIIQKYLLMARERKATKTLGIILGAFIVCWLPFFIISLVMPIH---------LAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK--- | |||||||||||||||||||
| 10 | 2rh1A | 0.26 | 0.26 | 0.86 | 3.83 | Download | -------------------DEVWVVGMGIVMSLIVLAIVFGNVLVITAIAKFERLQTVTNYFITSLACADLVMGLAVVPFGAAHILM------KMWTFGNFWCEFWTSIDVLCVTASIETLCVIAVDRYFAITSPFKYQSLLTKNKARVIILMVWIVSGLTSFLPIQFTNQAYAIASSIVSFYVPLVIMVFVYSRVFQEAKRQ-------LLKEHKALKTLGIIMGTFTLCWLPFFIVNIVHVIQDNLIR----KEVYILLNWIGYVNSGFNPLIYCR-SPDFRIAFQELLC----L | |||||||||||||||||||
| ||||||||||||||||||||||||||
| Top 5 Models predicted by GPCR-I-TASSER |
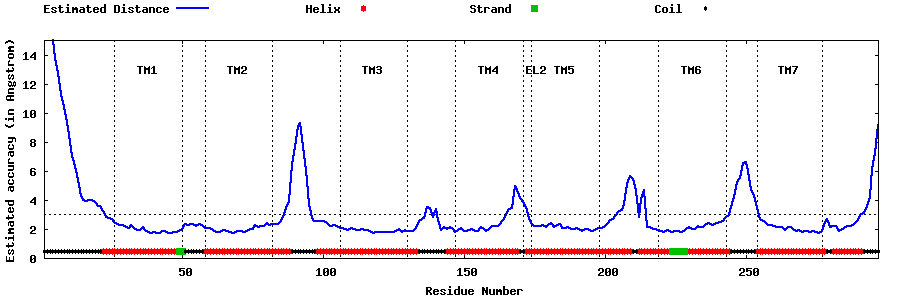
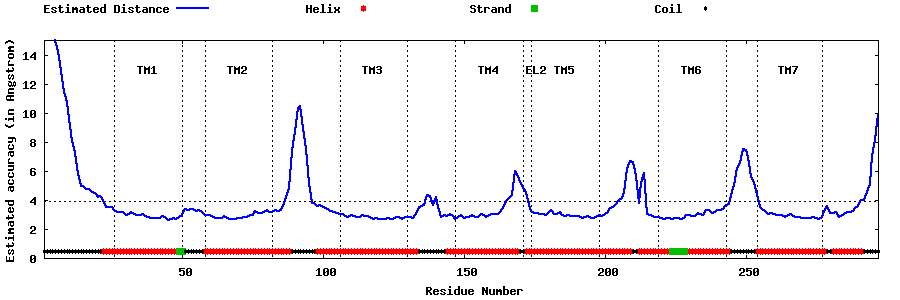
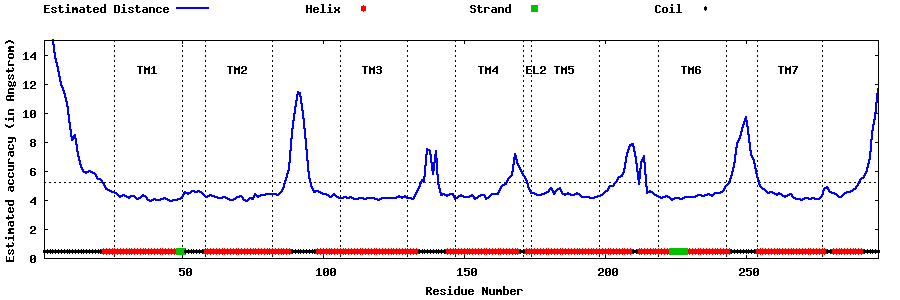
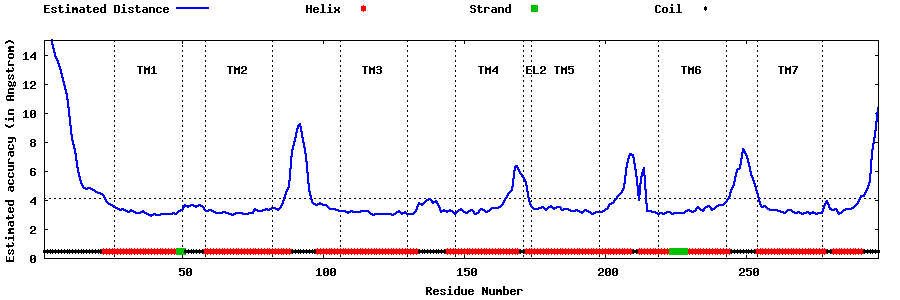
| Generated 3D models | Estimated local accuracy of models | ||
 | |||
|
|
|||
 | |||
|
| |||
 | |||
|
| |||
 | |||
|
| |||
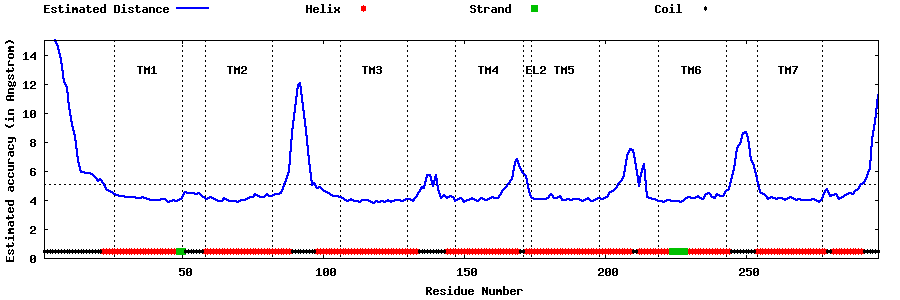 | |||
|
| |||
| Please cite following articles when you use the GPCR-I-TASSER server: | |
| J Zhang, J Yang, R Jang, Y Zhang. Hybrid structure modeling of G protein-coupled receptors in the human genome, submitted (2015). |