GPCR-I-TASSER results for Q16602
[Click on Q16602_results.tar.bz2 to download the tarball file including all modeling results listed on this page]
| Submitted Sequence |
| >Q16602 MEKKCTLNFLVLLPFFMILVTAELEESPEDSIQLGVTRNKIMTAQYECYQKIMQDPIQQA EGVYCNRTWDGWLCWNDVAAGTESMQLCPDYFQDFDPSEKVTKICDQDGNWFRHPASNRT WTNYTQCNVNTHEKVKTALNLFYLTIIGHGLSIASLLISLGIFFYFKSLSCQRITLHKNL FFSFVCNSVVTIIHLTAVANNQALVATNPVSCKVSQFIHLYLMGCNYFWMLCEGIYLHTL IVVAVFAEKQHLMWYYFLGWGFPLIPACIHAIARSLYYNDNCWISSDTHLLYIIHGPICA ALLVNLFFLLNIVRVLITKLKVTHQAESNLYMKAVRATLILVPLLGIEFVLIPWRPEGKI AEEVYDYIMHILMHFQGLLVSTIFCFFNGEVQAILRRNWNQYKIQFGNSFSNSEALRSAS YTVSTISDGPGYSHDCPSEHLNGKSIHDIENVLLKPENLYN |
| Predicted Secondary Structure |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 400 420 440 460 | | | | | | | | | | | | | | | | | | | | | | | MEKKCTLNFLVLLPFFMILVTAELEESPEDSIQLGVTRNKIMTAQYECYQKIMQDPIQQAEGVYCNRTWDGWLCWNDVAAGTESMQLCPDYFQDFDPSEKVTKICDQDGNWFRHPASNRTWTNYTQCNVNTHEKVKTALNLFYLTIIGHGLSIASLLISLGIFFYFKSLSCQRITLHKNLFFSFVCNSVVTIIHLTAVANNQALVATNPVSCKVSQFIHLYLMGCNYFWMLCEGIYLHTLIVVAVFAEKQHLMWYYFLGWGFPLIPACIHAIARSLYYNDNCWISSDTHLLYIIHGPICAALLVNLFFLLNIVRVLITKLKVTHQAESNLYMKAVRATLILVPLLGIEFVLIPWRPEGKIAEEVYDYIMHILMHFQGLLVSTIFCFFNGEVQAILRRNWNQYKIQFGNSFSNSEALRSASYTVSTISDGPGYSHDCPSEHLNGKSIHDIENVLLKPENLYN | |
| CCHCHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCCCCCCCCCCCCCCCSSSCCCCHHHHCCCCCCCSSSSSSSCCSSSSSCCCCCCCCCCCCCCCCCCCCHHHHHHHHHHHCCHHHHHHHHHHHHHHHHHHHHHHSSCCCHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHCHHCCCSSSSSSSSSSSCCCCCCCSSCCCCCCCSSSSCHHHHHHHHHHHHHHHHHHHHHCCHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHCCSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHSSSSCCHHHHHHHHHHHHCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC | |
| 92307999999999998614300156986301189999999999999999987476788889999987786002799999988965799345168988741466511885665147777765455432222222145553212330028888999999999997622121173089999999999999999887875305655453326899999999999999999999999999987767652566304453221031363268989999620014541223688100477603477998878999998773330011234523666667888889999999858855004530675099999999999998899987542337672889999999871276789997898999899998699998679899999866689988886625778877789 |
| Predicted Solvent Accessibility |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 400 420 440 460 | | | | | | | | | | | | | | | | | | | | | | | MEKKCTLNFLVLLPFFMILVTAELEESPEDSIQLGVTRNKIMTAQYECYQKIMQDPIQQAEGVYCNRTWDGWLCWNDVAAGTESMQLCPDYFQDFDPSEKVTKICDQDGNWFRHPASNRTWTNYTQCNVNTHEKVKTALNLFYLTIIGHGLSIASLLISLGIFFYFKSLSCQRITLHKNLFFSFVCNSVVTIIHLTAVANNQALVATNPVSCKVSQFIHLYLMGCNYFWMLCEGIYLHTLIVVAVFAEKQHLMWYYFLGWGFPLIPACIHAIARSLYYNDNCWISSDTHLLYIIHGPICAALLVNLFFLLNIVRVLITKLKVTHQAESNLYMKAVRATLILVPLLGIEFVLIPWRPEGKIAEEVYDYIMHILMHFQGLLVSTIFCFFNGEVQAILRRNWNQYKIQFGNSFSNSEALRSASYTVSTISDGPGYSHDCPSEHLNGKSIHDIENVLLKPENLYN | |
| 63200000001110000000213243347231314302420340033015303733446463310212000000014031331032200210223323220121022200112222122200000102212222222121220000000000000000000000010202132210000000000000000000000012222222111000000000000010000000000000000000101214320000000000010000000000000111000000123100000000000000000000000000000212333443323212200200000000103110000000123112100000000000300000010000013510310121023120434443344434334433323334333333434343145543633543314466438 | |
| Values range from 0 (buried residue) to 9 (highly exposed residue) | |
| Predicted normalized B-factor |

| Top 10 templates used by GPCR-I-TASSER |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380 400 420 440 460 | | | | | | | | | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCHCHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCCCCCCCCCCCCCCCSSSCCCCHHHHCCCCCCCSSSSSSSCCSSSSSCCCCCCCCCCCCCCCCCCCCHHHHHHHHHHHCCHHHHHHHHHHHHHHHHHHHHHHSSCCCHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHCHHCCCSSSSSSSSSSSCCCCCCCSSCCCCCCCSSSSCHHHHHHHHHHHHHHHHHHHHHCCHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHCCSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHSSSSCCHHHHHHHHHHHHCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC MEKKCTLNFLVLLPFFMILVTAELEESPEDSIQLGVTRNKIMTAQYECYQKIMQDPIQQAEGVYCNRTWDGWLCWNDVAAGTESMQLCPDYFQDFDPSEKVTKICDQDGNWFRHPASNRTWTNYTQCNVNTHEKVKTALNLFYLTIIGHGLSIASLLISLGIFFYFKSLSCQRITLHKNLFFSFVCNSVVTIIHLTAVANNQALVATNPVSCKVSQFIHLYLMGCNYFWMLCEGIYLHTLIVVAVFAEKQHLMWYYFLGWGFPLIPACIHAIARSLYYNDNCWISSDTHLLYIIHGPICAALLVNLFFLLNIVRVLITKLKVTHQAESNLYMKAVRATLILVPLLGIEFVLIPWRPEGKIAEEVYDYIMHILMHFQGLLVSTIFCFFNGEVQAILRRNWNQYKIQFGNSFSNSEALRSASYTVSTISDGPGYSHDCPSEHLNGKSIHDIENVLLKPENLYN | |||||||||||||||||||||||||
| 1 | 4l6rA | 0.23 | 0.24 | 0.81 | 3.42 | Download | --------------------------------DLEDNWETLNDNLKVIEK---ADNAAQVKDALTKMRAAALDAQKATPPKLEDKSPDSPEMKDFNEGKVKEAQAAAEQLKTTRNAYIQKYLMDGEEIEVQKEVAKMYSSFQVMYTVGYSLSLGALLLALAILGGLSKLHCTRNAIHANLFASFVLKASSVLVIDGL---LRTLSDGAVAGCRVAAVFMQYGIVANYCWLLVEGLYLHNLLGLATLPERSFFSLYLGIGWGAPMLFVVPWAVVKCLFENVQCWTNDNMGFWWILRFPVFLAILINFFIFVRIVQLLVAKLRARQMHHTDYKFRLAKSTLTLIPLLGVHEVVFAFVTDEHALRSAKLFFDLFLSSFQGLLVAVLYCFLNKEVQSELRRRWHRWRLGKVLWEERN------------------------------------------------ | |||||||||||||||||||
| 2 | 4l6rA | 0.25 | 0.24 | 0.80 | 1.87 | Download | --------ADLEDNWETLNDNLKVIEKADNAAQVKDALTKMRAAALDAQPKLEDKSPD------SPEMKDFRHGFDILNEG------KVKEAQAAAEQL--------------KTTRNAYIQKYLMDGEEIEEVAKMYSSFQVMYTVGYSLSLGALLLALAILGGLSKLHCTRNAIHANLFASFVLKASSVLVIDGLGAVAG---------CRVAAVFMQYGIVANYCWLLVEGLYLHNLLGLATLPERSFFSLYLGIGWGAPMLFVVPWAVVKCLFENVQCWTSNDNGFWWILRFPVFLAILINFFIFVRIVQLLVAKLRARQMHHTDYKFRLAKSTLTLIPLLGVHEVVFAFVTAQGTLRSAKLFFDLFLSSFQGLLVAVLYCFLNKEVQSELRRRWHRWRLGKVLWEERN------------------------------------------------ | |||||||||||||||||||
| 3 | 4l6rA | 0.24 | 0.24 | 0.82 | 1.86 | Download | -------------------------------ADLEDNWETLNDNLKVIEKA---DNAAQVKDALTKMRAAALDAQKATPPKLEDKSPDSPEMKDFNEGKVKEAQAAAEQLKTTRNAYIQKYLMDGEEIEVQKEVAKMYSSFQVMYTVGYSLSLGALLLALAILGGLSKLHCTRNAIHANLFASFVLKASSVLVIDGLLRTLSD---GAVAGCRVAAVFMQYGIVANYCWLLVEGLYLHNLLGLATLPERSFFSLYLGIGWGAPMLFVVPWAVVKCLFENVQCWTSNDNGFWWILRFPVFLAILINFFIFVRIVQLLVAKLRARQMHHTDYKFRLAKSTLTLIPLLGVHEVVFAFVTAQGTLRSAKLFFDLFLSSFQGLLVAVLYCFLNKEVQSELRRRWHRWRLGKVLWEERN------------------------------------------------ | |||||||||||||||||||
| 4 | 4k5yA | 0.33 | 0.21 | 0.54 | 3.92 | Download | ----------------------------------------------------------------------------------------------------------------------------------------HYHVAAIINYLGHCISLVALLVAFVLFLRARSIRCLRNIIHANLIAAFILRNATWFVVQLTM--SPEVHQSNVGWCRLVTAAYNYFHVTNFFWMFGEGCYLHTAIVLTNFEDRLRAWMFICIGWGVPFPIIVAWAIGKLYYDNEKCWAGKRPGVYYIYQGPMALVLLINFIFLFNIVRILMTKLRASTTSETIQARKAVKATLVLLPLLGITYMLAFVN---EVSRVVFIYFNAFLESFQGFFVSVFACFLNS------------------------------------------------------------------------ | |||||||||||||||||||
| 5 | 4k5yA | 0.32 | 0.21 | 0.54 | 4.50 | Download | ----------------------------------------------------------------------------------------------------------------------------------------HYHVAAIINYLGHCISLVALLVAFVLFLRARSIRCLRNIIHANLIAAFILRNATWFVVQLTM--SPEVHQSNVGWCRLVTAAYNYFHVTNFFWMFGEGCYLHTAIVLTFEYDRLRAWMFICIGWGVPFPIIVAWAIGKLYYDNEKCWAGKRPGVYYIYQGPMALVLLINFIFLFNIVRILMTKLRASTTSETIQARKAVKATLVLLPLLGITYMLAFVN---EVSRVVFIYFNAFLESFQGFFVSVFACFLNS------------------------------------------------------------------------ | |||||||||||||||||||
| 6 | 4l6rA | 0.23 | 0.24 | 0.81 | 3.11 | Download | --------------------------------DLEDNWETLNDNLKVIEKA---DNAAQVKDALTKMRAAALDAQKATPPKLEDKSPDSPEMKDFNEGKVKEAQAAAEQLKTTRNAYIQKYLMDGEEIEVQKEVAKMYSSFQVMYTVGYSLSLGALLLALAILGGLSKLHCTRNAIHANLFASFVLKASSVLVIDGLLRTL---SDGAVAGCRVAAVFMQYGIVANYCWLLVEGLYLHNLLGLATLPERSFFSLYLGIGWGAPMLFVVPWAVVKCLFENVQCWTSDNMGFWWILRFPVFLAILINFFIFVRIVQLLVAKLRARQMHHTDYKFRLAKSTLTLIPLLGVHEVVFAFVTAQGTLRSAKLFFDLFLSSFQGLLVAVLYCFLNKEVQSELRRRWHRWRLGKVLWEERN------------------------------------------------ | |||||||||||||||||||
| 7 | 4k5yA | 0.32 | 0.21 | 0.54 | 5.43 | Download | ----------------------------------------------------------------------------------------------------------------------------------------HYHVAAIINYLGHCISLVALLVAFVLFLRARSIRCLRNIIHANLIAAFILRNATWFVVQLTMS--PEVHQSNVGWCRLVTAAYNYFHVTNFFWMFGEGCYLHTAIVLTNEYDRLRAWMFICIGWGVPFPIIVAWAIGKLYYDNEKCWAGKRPGVYYIYQGPMALVLLINFIFLFNIVRILMTKLRASTTSETIQARKAVKATLVLLPLLGITYMLAFVN---EVSRVVFIYFNAFLESFQGFFVSVFACFLNS------------------------------------------------------------------------ | |||||||||||||||||||
| 8 | 4k5yA | 0.33 | 0.20 | 0.53 | 3.12 | Download | ----------------------------------------------------------------------------------------------------------------------------------------HYHVAAIINYLGHCISLVALLVAFVLFLRARSIRCLRNIIHANLIAAFILRNATWFVVQLTMS--PEVHQSNVGWCRLVTAAYNYFHVTNFFWMFGEGCYLHTAIVL---TDRLRAWMFICIGWGVPFPIIVAWAIGKLYYDNEKCWAGKRPYTDYIYQGPMALVLLINFIFLFNIVRILMTKLRASTTSETIQARKAVKATLVLLPLLGITYMLAFV---NEVSRVVFIYFNAFLESFQGFFVSVFACFLNS------------------------------------------------------------------------ | |||||||||||||||||||
| 9 | 4l6rA | 0.24 | 0.24 | 0.82 | 2.44 | Download | -------------------------------ADLEDNWETLNDNLKVIEKA---DNAAQVKDALTKMRAAALDAQKATPPKLEDKSPDSPEMKDFNEGKVKEAQAAAEQLKTTRNAYIQKYLMDGEEIEVQKEVAKMYSSFQVMYTVGYSLSLGALLLALAILGGLSKLHCTRNAIHANLFASFVLKASSVLVIDGLLRTL---SDGAVAGCRVAAVFMQYGIVANYCWLLVEGLYLHNLLGLATLPERSFFSLYLGIGWGAPMLFVVPWAVVKCLFENVQCWTSNDNMFWWILRFPVFLAILINFFIFVRIVQLLVAKLRARQMHHTDYKFRLAKSTLTLIPLLGVHEVVFAFVTDEHALRSAKLFFDLFLSSFQGLLVAVLYCFLNKEVQSELRRRWHRWRLGKVLWEERN------------------------------------------------ | |||||||||||||||||||
| 10 | 4l6rA | 0.23 | 0.24 | 0.82 | 2.28 | Download | A-------------------------------DLEDNWETLNDNLKVIEK---ADNAAQVKDALTKMRAAALDAQKATPPKLEDKSPDSPEMKLANEGKVKEAQAAAEQLKTTRNAYIQKYLMDGEEIEVQKEVAKMYSSFQVMYTVGYSLSLGALLLALAILGGLSKLHCTRNAIHANLFASFVLKASSVLVIDGL---LRTLSDGAVAGCRVAAVFMQYGIVANYCWLLVEGLYLHNLLGLATLPERSFFSLYLGIGWGAPMLFVVPWAVVKCLFENVQCWTSNDNMGFWILRFPVFLAILINFFIFVRIVQLLVAKLRARQMHHTDYKFRLAKSTLTLIPLLGVHEVVFAFVTDEHALRSAKLFFDLFLSSFQGLLVAVLYCFLNKEVQSELRRRWHRWRLGKVLWEERN------------------------------------------------ | |||||||||||||||||||
| ||||||||||||||||||||||||||
| Top 5 Models predicted by GPCR-I-TASSER |
| Generated 3D models | Estimated local accuracy of models | ||
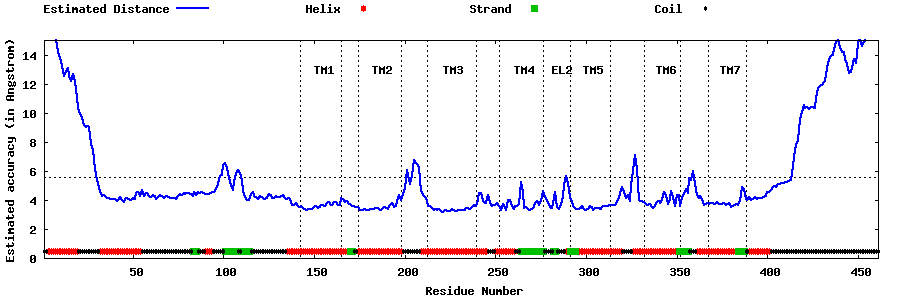 | |||
|
|
|||
| Please cite following articles when you use the GPCR-I-TASSER server: | |
| J Zhang, J Yang, R Jang, Y Zhang. Hybrid structure modeling of G protein-coupled receptors in the human genome, submitted (2015). |