GPCR-I-TASSER results for Q6IFG1
[Click on Q6IFG1_results.tar.bz2 to download the tarball file including all modeling results listed on this page]
| Submitted Sequence |
| >Q6IFG1 MAGRMSTSNHTQFHPSSFLLLGIPGLEDVHIWIGVPFFFVYLVALLGNTALLFVIQTEQS LHEPMYYFLAMLDSIDLGLSTATIPKMLGIFWFNTKEISFGGCLSHMFFIHFFTAMESIV LVAMAFDRYIAICKPLRYTMILTSKIISLIAGIAVLRSLYMVVPLVFLLLRLPFCGHRII PHTYCEHMGIARLACASIKVNIRFGLGNISLLLLDVILIILSYVRILYAVFCLPSWEARL KALNTCGSHIGVILAFFTPAFFSFLTHRFGHNIPQYIHIILANLYVVVPPALNPVIYGVR TKQIRERVLRIFLKTNH |
| Predicted Secondary Structure |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MAGRMSTSNHTQFHPSSFLLLGIPGLEDVHIWIGVPFFFVYLVALLGNTALLFVIQTEQSLHEPMYYFLAMLDSIDLGLSTATIPKMLGIFWFNTKEISFGGCLSHMFFIHFFTAMESIVLVAMAFDRYIAICKPLRYTMILTSKIISLIAGIAVLRSLYMVVPLVFLLLRLPFCGHRIIPHTYCEHMGIARLACASIKVNIRFGLGNISLLLLDVILIILSYVRILYAVFCLPSWEARLKALNTCGSHIGVILAFFTPAFFSFLTHRFGHNIPQYIHIILANLYVVVPPALNPVIYGVRTKQIRERVLRIFLKTNH | |
| CCCCCCCCCCCCCCCCCCSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCHHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHCHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCSSSCCCHHHHHHHHHHHHHCCCC | |
| 98876688889880650026889898668899999999999999999999999884788754308999999999999999966999999995699868888899999999999999999999998342775166644631288899999999999999999998999996389999894686000226568881578348589999999999998999999999999998168897788898550699999999999989998314313798880899999999973786646812206579999999998510469 |
| Predicted Solvent Accessibility |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MAGRMSTSNHTQFHPSSFLLLGIPGLEDVHIWIGVPFFFVYLVALLGNTALLFVIQTEQSLHEPMYYFLAMLDSIDLGLSTATIPKMLGIFWFNTKEISFGGCLSHMFFIHFFTAMESIVLVAMAFDRYIAICKPLRYTMILTSKIISLIAGIAVLRSLYMVVPLVFLLLRLPFCGHRIIPHTYCEHMGIARLACASIKVNIRFGLGNISLLLLDVILIILSYVRILYAVFCLPSWEARLKALNTCGSHIGVILAFFTPAFFSFLTHRFGHNIPQYIHIILANLYVVVPPALNPVIYGVRTKQIRERVLRIFLKTNH | |
| 74551443131423211010000022342010002302301220231121000001004300200020001001201000101203000000043460304000000120131133100000000200000002101000000330001000100221101120112102002104622010000102200300022030023102303333333332033012200200030216602320010000000002113321321000012234123201000012022311330030000103301400240034468 | |
| Values range from 0 (buried residue) to 9 (highly exposed residue) | |
| Predicted normalized B-factor |

| Top 10 templates used by GPCR-I-TASSER |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCCCCCCCCCCCSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCHHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHCHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCSSSCCCHHHHHHHHHHHHHCCCC MAGRMSTSNHTQFHPSSFLLLGIPGLEDVHIWIGVPFFFVYLVALLGNTALLFVIQTEQSLHEPMYYFLAMLDSIDLGLSTATIPKMLGIFWFNTKEISFGGCLSHMFFIHFFTAMESIVLVAMAFDRYIAICKPLRYTMILTSKIISLIAGIAVLRSLYMVVPLVFLLLRLPFCGHRIIPHTYCEHMGIARLACASIKVNIRFGLGNISLLLLDVILIILSYVRILYAVFCLPSWEARLKALNTCGSHIGVILAFFTPAFFSFLTHRFGHNIPQYIHIILANLYVVVPPALNPVIYGVRTKQIRERVLRIFLKTNH | |||||||||||||||||||||||||
| 1 | 4iaqA | 0.17 | 0.19 | 0.83 | 1.86 | Download | ------------------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTG--RWTLVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLP-------PFFCVVN-----------------TDHILYTVYSTVGAFY--FPTLLLIALYGRIYVEARSRIMAARERKATKTLGIILGAFIVCWLPFFIISLVMPI-----HLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK-- | |||||||||||||||||||
| 2 | 3emlA | 0.20 | 0.24 | 0.87 | 2.50 | Download | -------------------------IM-GSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIST--GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDV----------VPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCFTFFC---PDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHRQ | |||||||||||||||||||
| 3 | 3uonA | 0.17 | 0.19 | 0.87 | 2.54 | Download | --------------------------TFEVVFIVLVAGSLSLVTIIGNILVMVSIKVNRHLQTVNNYFLFSLACADLIIGVFSMNLYTLYTVIGYWPLGPVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPVKRTTKMAGMMIAAAWVLSFILWAPAILFWQFIVG--VRTVEDGECYIQFFS---------NAAVTFGTIAAFYLPVIIMTVLYWHISRASKSRINISREKKVTRTILAILLAFIITWAPYNVMVLINTFCAPCIPNTVWTIGYWLCYINSTINPACYALCNATFKKTFKHLLM---- | |||||||||||||||||||
| 4 | 4bvnA | 0.19 | 0.21 | 0.87 | 2.06 | Download | -------------------------LQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASVETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMMH----WWRDEDPQALKCYQD----PGCCDFVTNRAYAIASSISFYIPLLIMIFVALRVYREAKE----MREHKALKTLGIIMGVFTLCWLPFFLVNIVNVFNRDLVPKWLFVAFNWLGYANSAMNPIILC-RSPDFRKAFKRLLA---- | |||||||||||||||||||
| 5 | 3emlA | 0.20 | 0.24 | 0.87 | 2.79 | Download | ---------------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIST--GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCFTFFC---PDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL | |||||||||||||||||||
| 6 | 4bvnA | 0.19 | 0.21 | 0.87 | 2.98 | Download | -------------------------LQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASVETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMMHWW----RDEDPQALKCYQDP----GCCDFVTNRAYAISSIISFYIPLLIMIFVALRVYREAKEQ---MREHKALKTLGIIMGVFTLCWLPFFLVNIVNVFNRDVPKWLF-VAFNWLGYANSAMNPIILC-RSPDFRKAFKRLLA---- | |||||||||||||||||||
| 7 | 4buoA | 0.17 | 0.23 | 0.91 | 3.12 | Download | --------NSDLDVNTD---------IYSKVLVTAIYLALFVVGTVGNSVTLFTLARKKSLQSTVDYYLGSLALSDLLILLLAMPVELYNFIWVHHPWAFAGCRGYYFLRDACTYATALNVVSLSVELYLAICHPFKAKTLMSRSRTKKFISAIWLASALLAIPMLFTMGLQNLSGDGTHPGGTATLKVVIQVNTFMSFLFPMLVASILNTVIANKLTVMVHQGRVQALRRGVLVLRAVVIAFVVCWLPYHVRRLMFCYI--------SDEQWTYHYFYMLTNALVYVSAAINPILYNLVSANFRQVFLSTL----- | |||||||||||||||||||
| 8 | 3emlA | 0.21 | 0.24 | 0.85 | 3.25 | Download | -------------------------I--GSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITISF----CAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFED-----------VPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCFTFF-----DCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHRQ | |||||||||||||||||||
| 9 | 3emlA | 0.20 | 0.24 | 0.87 | 4.00 | Download | IMG--------------------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAI--TISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVPMNYMVYFNFFACVL----------VPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLP-LHIINCFTFF--CPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHRQ | |||||||||||||||||||
| 10 | 3emlA | 0.21 | 0.24 | 0.82 | 2.85 | Download | ------------------------------------ELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS--TGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQSQGCGEGQVACLFEDV--------VPMNYMVYFNFFCVLVPLLLMLGVYLRIFLAARRQ-----LVHAAKSLAIIVGLFALCWLPLHIINCFTFFCPDCAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKII----- | |||||||||||||||||||
| ||||||||||||||||||||||||||
| Top 5 Models predicted by GPCR-I-TASSER |
| Generated 3D models | Estimated local accuracy of models | ||
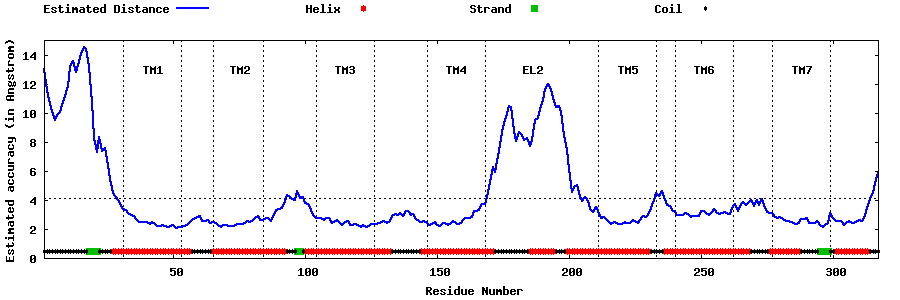 | |||
|
|
|||
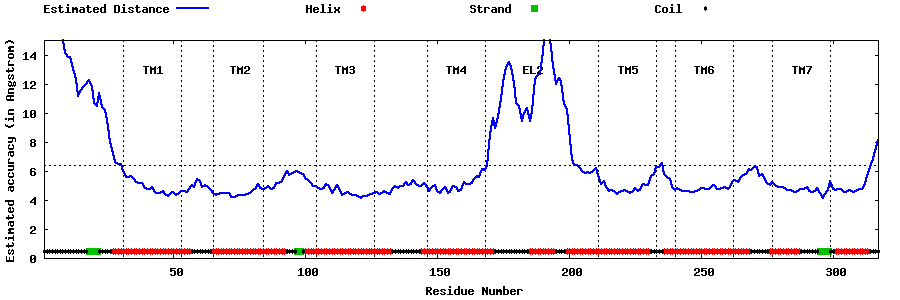 | |||
|
| |||
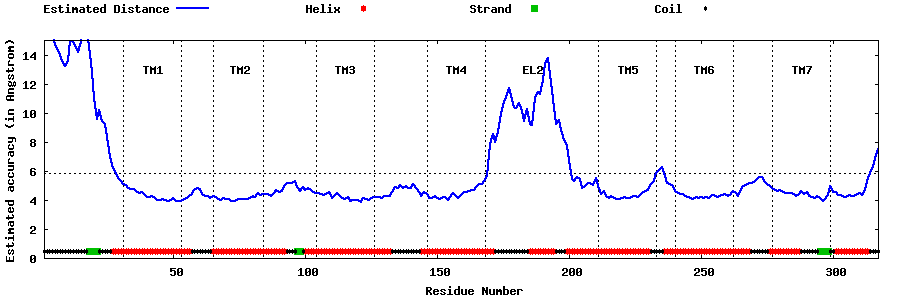 | |||
|
| |||
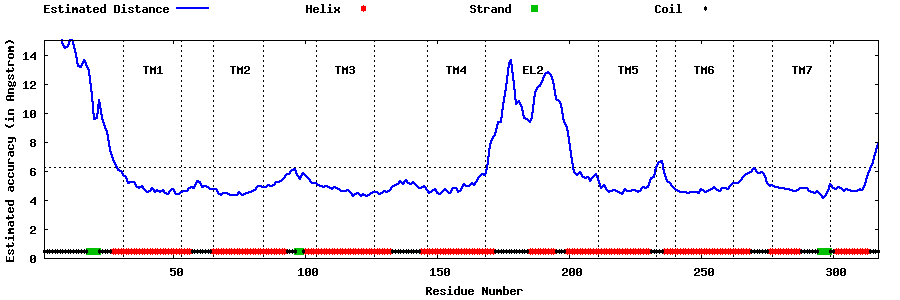 | |||
|
| |||
 | |||
|
| |||
| Please cite following articles when you use the GPCR-I-TASSER server: | |
| J Zhang, J Yang, R Jang, Y Zhang. Hybrid structure modeling of G protein-coupled receptors in the human genome, submitted (2015). |