GPCR-I-TASSER results for Q8NGA6
[Click on Q8NGA6_results.tar.bz2 to download the tarball file including all modeling results listed on this page]
| Submitted Sequence |
| >Q8NGA6 MQGLNHTSVSEFILVGFSAFPHLQLMLFLLFLLMYLFTLLGNLLIMATVWSERSLHMPMY LFLCALSITEILYTVAIIPRMLADLLSTQRSIAFLACASQMFFSFSFGFTHSFLLTVMGY DRYVAICHPLRYNVLMSLRGCTCRVGCSWAGGLVMGMVVTSAIFHLAFCGHKEIHHFFCH VPPLLKLACGDDVLVVAKGVGLVCITALLGCFLLILLSYAFIVAAILKIPSAEGRNKAFS TCASHLTVVVVHYGFASVIYLKPKGPQSPEGDTLMGITYTVLTPFLSPIIFSLRNKELKV AMKKTCFTKLFPQNC |
| Predicted Secondary Structure |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MQGLNHTSVSEFILVGFSAFPHLQLMLFLLFLLMYLFTLLGNLLIMATVWSERSLHMPMYLFLCALSITEILYTVAIIPRMLADLLSTQRSIAFLACASQMFFSFSFGFTHSFLLTVMGYDRYVAICHPLRYNVLMSLRGCTCRVGCSWAGGLVMGMVVTSAIFHLAFCGHKEIHHFFCHVPPLLKLACGDDVLVVAKGVGLVCITALLGCFLLILLSYAFIVAAILKIPSAEGRNKAFSTCASHLTVVVVHYGFASVIYLKPKGPQSPEGDTLMGITYTVLTPFLSPIIFSLRNKELKVAMKKTCFTKLFPQNC | |
| CCCCCCCSSSSSSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHCCHHHHHHHHCCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCCCCCHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSHHHHHHCCCCHHHCCCCHHHHHHHHHHHHCCCCCCCC | |
| 999887356787786689885179999999999999999989999798871887567489998889999888883088999898556996785899999999999999999999999976406740754447850377389999999999999999999999805378997978886248288888854684357899999999999999999999999999999702866266753221658689969998721414882789989887880899866415543145431046599999999998506688889 |
| Predicted Solvent Accessibility |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MQGLNHTSVSEFILVGFSAFPHLQLMLFLLFLLMYLFTLLGNLLIMATVWSERSLHMPMYLFLCALSITEILYTVAIIPRMLADLLSTQRSIAFLACASQMFFSFSFGFTHSFLLTVMGYDRYVAICHPLRYNVLMSLRGCTCRVGCSWAGGLVMGMVVTSAIFHLAFCGHKEIHHFFCHVPPLLKLACGDDVLVVAKGVGLVCITALLGCFLLILLSYAFIVAAILKIPSAEGRNKAFSTCASHLTVVVVHYGFASVIYLKPKGPQSPEGDTLMGITYTVLTPFLSPIIFSLRNKELKVAMKKTCFTKLFPQNC | |
| 865413020000000000432401110013013312310332320020010033000000200200011022011031030001011553201020021012001000210010000000000000021020003003300000012001100310310011001020036140200000221002000111330011112231333233122002302320000002031363231000000001000001120010000103063244341000031033213310300001032014002200333313563 | |
| Values range from 0 (buried residue) to 9 (highly exposed residue) | |
| Predicted normalized B-factor |

| Top 10 templates used by GPCR-I-TASSER |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCSSSSSSSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHHHHHHCCHHHHHHHHCCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCCCCCHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCHHHCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSHHHHHHCCCCHHHCCCCHHHHHHHHHHHHCCCCCCCC MQGLNHTSVSEFILVGFSAFPHLQLMLFLLFLLMYLFTLLGNLLIMATVWSERSLHMPMYLFLCALSITEILYTVAIIPRMLADLLSTQRSIAFLACASQMFFSFSFGFTHSFLLTVMGYDRYVAICHPLRYNVLMSLRGCTCRVGCSWAGGLVMGMVVTSAIFHLAFCGHKEIHHFFCHVPPLLKLACGDDVLVVAKGVGLVCITALLGCFLLILLSYAFIVAAILKIPSAEGRNKAFSTCASHLTVVVVHYGFASVIYLKPKGPQSPEGDTLMGITYTVLTPFLSPIIFSLRNKELKVAMKKTCFTKLFPQNC | |||||||||||||||||||||||||
| 1 | 3v2yA | 0.21 | 0.24 | 0.84 | 2.14 | Download | ------------------DKENSIKLTSVVFILICCFIILENIFVLLTIWKTKKFHRPMYYFIGNLALSDLLAGVAYTANLLLSGATTYK-LTPAQWFLREGSMFVALSASVFSLLAIAIERYITMLKN--------NFRLFLLISACWVISLILGG--------LPIMGWNCISA---------LSSCSTVLPLYHKHYILFCTTVFTLLLLSIVILYCRIYSLVRTRNSRSSEVALLKTVIIVLSVFIACWAPLFILLLLDVGCKVKTCDILFRLVLAVLNSGTNPIIYTLTNKEMRRAFIRIMGRPL----- | |||||||||||||||||||
| 2 | 4iaqA | 0.20 | 0.19 | 0.83 | 2.35 | Download | ------------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGR----WVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISL---------PPCVVNTDH------------------ILYTVYSTVGAFY---FPTLLLIALYGRIYVEARSRIIQKRERKATKTLGIILGAFIVCWLPFFIISLVMPIH---LAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK------ | |||||||||||||||||||
| 3 | 3emlA | 0.21 | 0.22 | 0.88 | 3.69 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP------------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHI-INCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ-- | |||||||||||||||||||
| 4 | 3uonA | 0.16 | 0.18 | 0.87 | 2.55 | Download | --------------------TFEVVFIVLVAGSLSLVTIIGNILVMVSIKVNRHLQTVNNYFLFSLACADLIIGVFSMNLYTLYTVIGYWPLGPVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPVKRTTKMAGMMIAAAWVLSFILWAPAILFWQFIV--GVRTVEDGECYIQFFS----------NAAVTFGTAIAAFYLPVIIMTVLYWHISRASKSRINISREKKVTRTILAILLAFIITWAPYNVMVLINTFPCIPNTVWTIGYWLCYINSTINPACYALCNATFKKTFKHLLM-------- | |||||||||||||||||||
| 5 | 4bvnA | 0.17 | 0.18 | 0.87 | 2.04 | Download | -------------------LQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASVETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMM----HWWRDEDPQALKCYQD----PGCCDFVTNRAYAI-ASSIISFYIPLLIMIFVALRVYREAKE-----REHKALKTLGIIMGVFTLCWLPFFLVNIVNVFDLVPKWLFVAFNWLGYANSAMNPIILC-RSPDFRKAFKRLLA-------- | |||||||||||||||||||
| 6 | 3emlA | 0.21 | 0.22 | 0.88 | 4.16 | Download | ---------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP------------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCF-TFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ-- | |||||||||||||||||||
| 7 | 4bvnA | 0.17 | 0.18 | 0.88 | 2.98 | Download | ------------------LSQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASVETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMMHWW----RDEDPQALKCYQDP----GCCDFVTNRAYAIA-SSIISFYIPLLIMIFVALRVYREAKEQ---MREHKALKTLGIIMGVFTLCWLPFFLVNIVNNRDLVPKWLFVAFNWLGYANSAMNPIILC-RSPDFRKAFKRLLA-------- | |||||||||||||||||||
| 8 | 2z73A | 0.16 | 0.21 | 0.93 | 2.62 | Download | -ETWNPSIVVHPHWREFDQVPAVYYSLGIFIGICGIIGCGGNGIVIYLFTKTKSLQTPANMFIINLAFSDFTFSLVNGPLMTISCFLKKWIFGFAACKVYGFIGGIFGFMSIMTMAMISIDRYNVIGRPMAASKKMSHRRAFIMIIFVWLWSVLWAIGPIFGTLEGVLCNSRD-----------------STTRSNILCMFILG---FFGPILIIFFCYFNIVMAQAGANAEMRLAKISIVIVSQFLLSWSPYAVVALLAQFGPLEWVTPYAAQLPVMFAKASAIHNPMIYSVSHPKFREAISQTFPWVLTCCQF | |||||||||||||||||||
| 9 | 3emlA | 0.20 | 0.22 | 0.88 | 5.25 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS--TGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVP------------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAII-VGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ-- | |||||||||||||||||||
| 10 | 3emlA | 0.21 | 0.22 | 0.88 | 5.68 | Download | I--------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVPMNYMVYFNFF------------ACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWL-PLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ-- | |||||||||||||||||||
| ||||||||||||||||||||||||||
| Top 5 Models predicted by GPCR-I-TASSER |
| Generated 3D models | Estimated local accuracy of models | ||
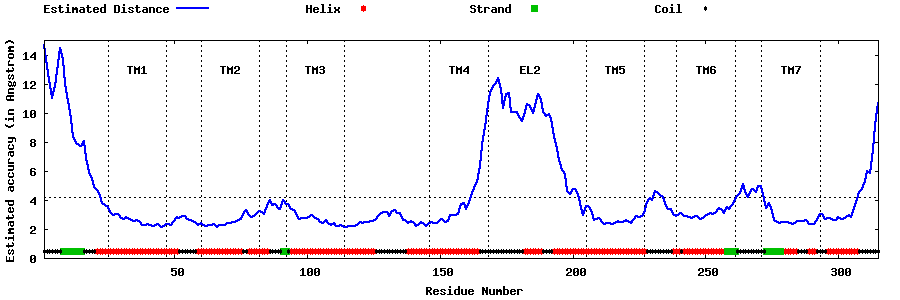 | |||
|
|
|||
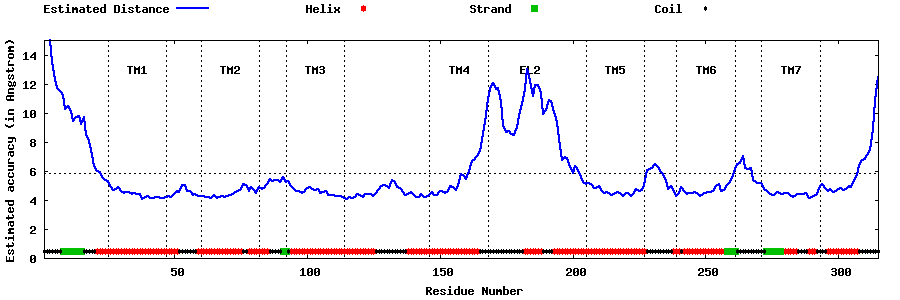 | |||
|
| |||
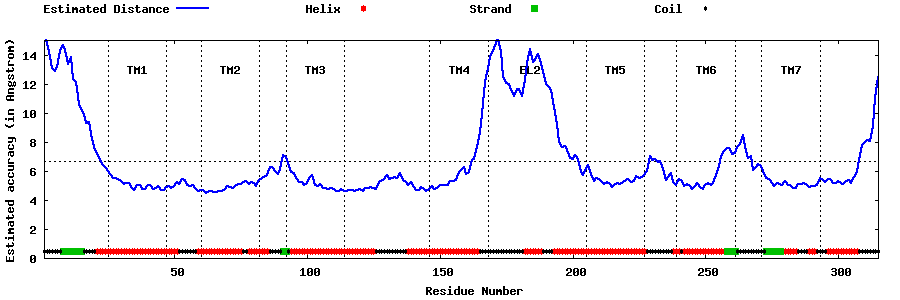 | |||
|
| |||
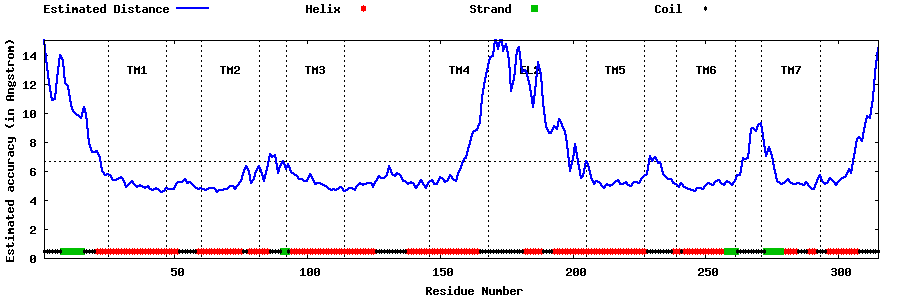 | |||
|
| |||
 | |||
|
| |||
| Please cite following articles when you use the GPCR-I-TASSER server: | |
| J Zhang, J Yang, R Jang, Y Zhang. Hybrid structure modeling of G protein-coupled receptors in the human genome, submitted (2015). |