GPCR-I-TASSER results for Q8NGG6
[Click on Q8NGG6_results.tar.bz2 to download the tarball file including all modeling results listed on this page]
| Submitted Sequence |
| >Q8NGG6 MAAKNSSVTEFILEGLTHQPGLRIPLFFLFLGFYTVTVVGNLGLITLIGLNSHLHTPMYF FLFNLSLIDFCFSTTITPKMLMSFVSRKNIISFTGCMTQLFFFCFFVVSESFILSAMAYD RYVAICNPLLYTVTMSCQVCLLLLLGAYGMGFAGAMAHTGSIMNLTFCADNLVNHFMCDI LPLLELSCNSSYMNELVVFIVVAVDVGMPIVTVFISYALILSSILHNSSTEGRSKAFSTC SSHIIVVSLFFGSGAFMYLKPLSILPLEQGKVSSLFYTIIVPVLNPLIYSLRNKDVKVAL RRTLGRKIFS |
| Predicted Secondary Structure |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MAAKNSSVTEFILEGLTHQPGLRIPLFFLFLGFYTVTVVGNLGLITLIGLNSHLHTPMYFFLFNLSLIDFCFSTTITPKMLMSFVSRKNIISFTGCMTQLFFFCFFVVSESFILSAMAYDRYVAICNPLLYTVTMSCQVCLLLLLGAYGMGFAGAMAHTGSIMNLTFCADNLVNHFMCDILPLLELSCNSSYMNELVVFIVVAVDVGMPIVTVFISYALILSSILHNSSTEGRSKAFSTCSSHIIVVSLFFGSGAFMYLKPLSILPLEQGKVSSLFYTIIVPVLNPLIYSLRNKDVKVALRRTLGRKIFS | |
| CCCCCCSCSSSSSSCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCHHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCSCCCCCCCCCHHHCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSSCCCHHCCCCHHHCCCCHHHHHHHHHHHHCCCCC | |
| 9999866043678648999260899999999999999998989999996188877738888767998844721256099999871489788489999999999999999999999998650452062101881267889999999999999999999999984540789990487335818887670568627788899999999999999999999999999802677676754321558889979999844412484789988787897899872110412435644046598999999998211589 |
| Predicted Solvent Accessibility |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MAAKNSSVTEFILEGLTHQPGLRIPLFFLFLGFYTVTVVGNLGLITLIGLNSHLHTPMYFFLFNLSLIDFCFSTTITPKMLMSFVSRKNIISFTGCMTQLFFFCFFVVSESFILSAMAYDRYVAICNPLLYTVTMSCQVCLLLLLGAYGMGFAGAMAHTGSIMNLTFCADNLVNHFMCDILPLLELSCNSSYMNELVVFIVVAVDVGMPIVTVFISYALILSSILHNSSTEGRSKAFSTCSSHIIVVSLFFGSGAFMYLKPLSILPLEQGKVSSLFYTIIVPVLNPLIYSLRNKDVKVALRRTLGRKIFS | |
| 8764313001000000043240100001303331321333331002001000300000010020000100110000003000200254220102000000100000020001000000000000001112020300330000002201210130030101100303004412010000032000200013231101100220132233123103303310110001031361231010011002100101320110000003253133341000021032103300300002132014002200533327 | |
| Values range from 0 (buried residue) to 9 (highly exposed residue) | |
| Predicted normalized B-factor |

| Top 10 templates used by GPCR-I-TASSER |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCSCSSSSSSCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCHHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCSCCCCCCCCCHHHCHHHHHHHHHHHHHHHHSSSSCCCCCCCCCCCCSSSSSSCCCHHCCCCHHHCCCCHHHHHHHHHHHHCCCCC MAAKNSSVTEFILEGLTHQPGLRIPLFFLFLGFYTVTVVGNLGLITLIGLNSHLHTPMYFFLFNLSLIDFCFSTTITPKMLMSFVSRKNIISFTGCMTQLFFFCFFVVSESFILSAMAYDRYVAICNPLLYTVTMSCQVCLLLLLGAYGMGFAGAMAHTGSIMNLTFCADNLVNHFMCDILPLLELSCNSSYMNELVVFIVVAVDVGMPIVTVFISYALILSSILHNSSTEGRSKAFSTCSSHIIVVSLFFGSGAFMYLKPLSILPLEQGKVSSLFYTIIVPVLNPLIYSLRNKDVKVALRRTLGRKIFS | |||||||||||||||||||||||||
| 1 | 4iaqA | 0.16 | 0.19 | 0.89 | 2.40 | Download | -----------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISL-------PPFFWRQAS--------------ECVVNTDHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIIQLMAARERKATKTLGIILGAFIVCWLPFFIISLVMPIHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK--- | |||||||||||||||||||
| 2 | 3emlA | 0.18 | 0.24 | 0.89 | 3.78 | Download | -------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAI-IVGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLR | |||||||||||||||||||
| 3 | 3uonA | 0.17 | 0.22 | 0.89 | 2.55 | Download | -------------------TFEVVFIVLVAGSLSLVTIIGNILVMVSIKVNRHLQTVNNYFLFSLACADLIIGVFSMNLYTLYTVIGYWPLGPVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPVKRTTKMAGMMIAAAWVLSFILWAPAILFWQFIV--GVRTVEDGECYIQFFS---------NAAVTFGTAIAAFYLPVIIMTVLYWHISRASKSRINPSREKKVTRTILAILLAFIITWAPYNVMVLINTFCAIPNTVWTIGYWLCYINSTINPACYALCNATFKKTFKHLLM----- | |||||||||||||||||||
| 4 | 4bvnA | 0.16 | 0.21 | 0.89 | 2.08 | Download | -----------------LSQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASVETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMMH----WWRDEDPQALKCYQD----PGCCDFVTNRAYAIASSIISFYIPLLIMIFVALRVYREAKE----MREHKALKTLGIIMGVFTLCWLPFFLVNIVNVFNRDPKWLFVAFNWLGYANSAMNPIILC-RSPDFRKAFKRLLA----- | |||||||||||||||||||
| 5 | 3emlA | 0.18 | 0.24 | 0.89 | 4.08 | Download | --------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCF-TFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLR | |||||||||||||||||||
| 6 | 4bvnA | 0.17 | 0.21 | 0.89 | 2.97 | Download | ------------------SQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASVETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMMHWW----RDEDPQALKCYQDP----GCCDFVTNRAYAIASSIISFYIPLLIMIFVALRVYREAKEQI--MREHKALKTLGIIMGVFTLCWLPFFLVNIVNRDLVP-KWLFVAFNWLGYANSAMNPIILC-RSPDFRKAFKRLLA----- | |||||||||||||||||||
| 7 | 4ea3A | 0.19 | 0.22 | 0.84 | 2.81 | Download | ------------------PLGLKVTIVGLYLAVCVGGLLGNCLVMYVILRHTKMKTATNIYIFNLALADTLVLLT-LPFQGTDILLGFWPFGNALCKTVIAIDYYNMFTSTFTLTAMSVDRYVAICHPTSSKAQAVNVAIWALASVVGVPVAIMGSAQVEDEIECLVEIPTPQDYWGPVFAICIFLFSF-----------------IVPVLVISVCYSLMIRRLRGVRLLSGSVAVFVGCWTPVQVFVLAQGLG-----VQPSSETAVAILRFCTALGYVNSCLNPILYAFLDENFKACFR--------- | |||||||||||||||||||
| 8 | 3emlA | 0.18 | 0.24 | 0.88 | 5.79 | Download | ---------------------ISSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAII-VGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLR | |||||||||||||||||||
| 9 | 3emlA | 0.18 | 0.24 | 0.89 | 5.56 | Download | I-------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPL-----------LLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALC-WLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLR | |||||||||||||||||||
| 10 | 3emlA | 0.17 | 0.24 | 0.86 | 2.82 | Download | --------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS--TGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQSQGCGEGQVACLFEDV--------VPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQ-----LVHAAKSLAIIVGLFALCWLPLHIINCFTFFCHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKI------- | |||||||||||||||||||
| ||||||||||||||||||||||||||
| Top 5 Models predicted by GPCR-I-TASSER |
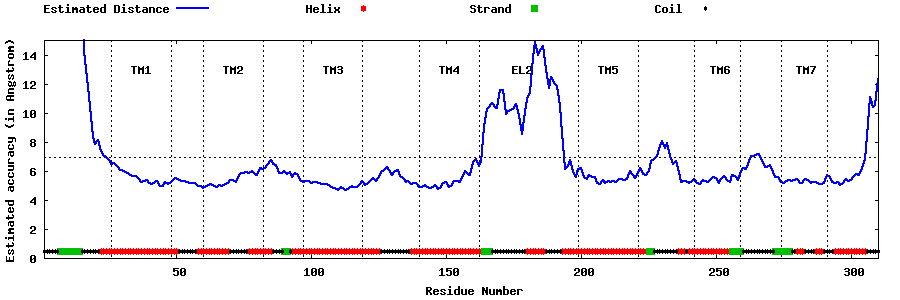
| Generated 3D models | Estimated local accuracy of models | ||
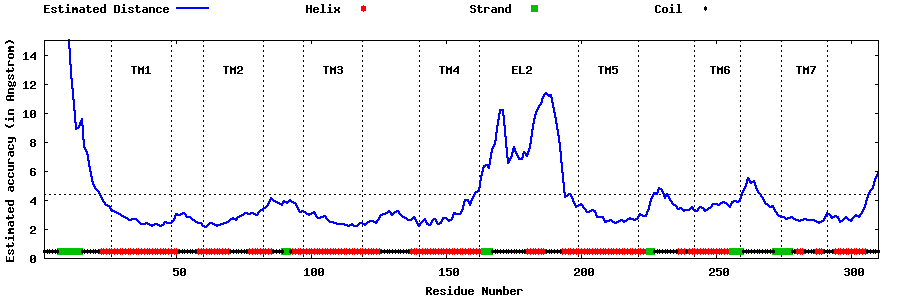 | |||
|
|
|||
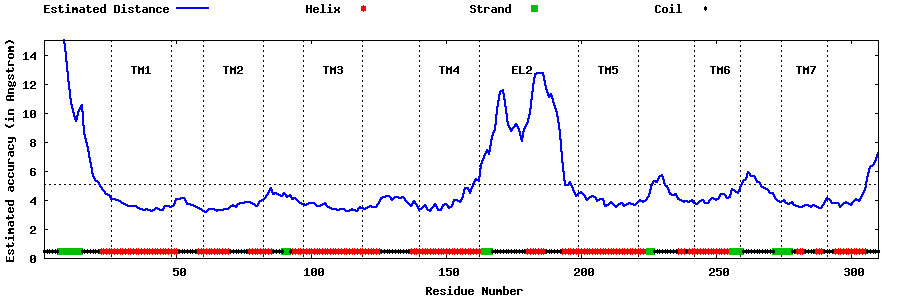 | |||
|
| |||
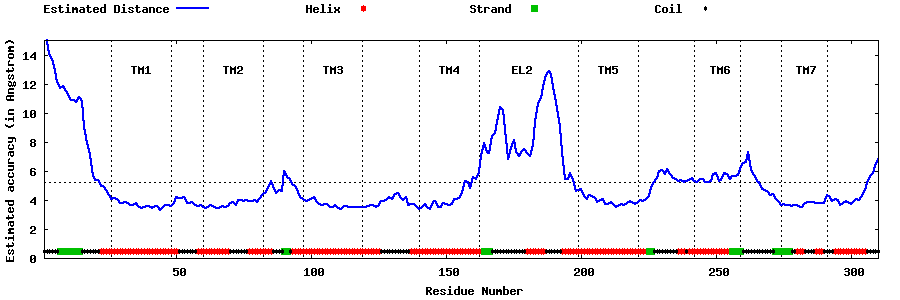 | |||
|
| |||
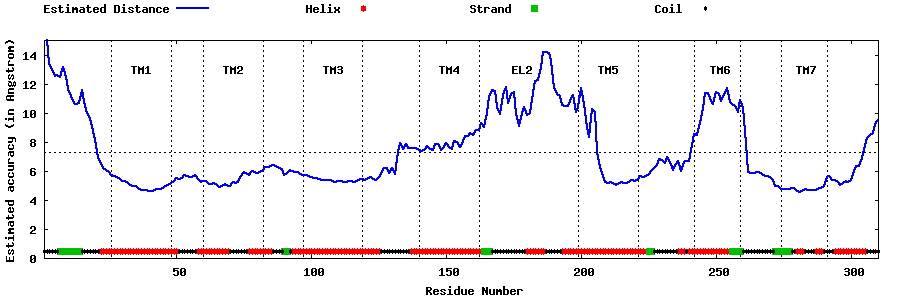 | |||
|
| |||
 | |||
|
| |||
| Please cite following articles when you use the GPCR-I-TASSER server: | |
| J Zhang, J Yang, R Jang, Y Zhang. Hybrid structure modeling of G protein-coupled receptors in the human genome, submitted (2015). |