GPCR-I-TASSER results for Q8NGP8
[Click on Q8NGP8_results.tar.bz2 to download the tarball file including all modeling results listed on this page]
| Submitted Sequence |
| >Q8NGP8 MFSPNHTIVTEFILLGLTDDPVLEKILFGVFLAIYLITLAGNLCMILLIRTNSHLQTPMY FFLGHLSFVDICYSSNVTPNMLHNFLSEQKTISYAGCFTQCLLFIALVITEFYILASMAL DRYVAICSPLHYSSRMSKNICVCLVTIPYMYGFLSGFSQSLLTFHLSFCGSLEINHFYCA DPPLIMLACSDTRVKKMAMFVVAGFNLSSSLFIILLSYLFIFAAIFRIRSAEGRHKAFST CASHLTIVTLFYGTLFCMYVRPPSEKSVEESKITAVFYTFLSPMLNPLIYSLRNTDVILA MQQMIRGKSFHKIAV |
| Predicted Secondary Structure |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MFSPNHTIVTEFILLGLTDDPVLEKILFGVFLAIYLITLAGNLCMILLIRTNSHLQTPMYFFLGHLSFVDICYSSNVTPNMLHNFLSEQKTISYAGCFTQCLLFIALVITEFYILASMALDRYVAICSPLHYSSRMSKNICVCLVTIPYMYGFLSGFSQSLLTFHLSFCGSLEINHFYCADPPLIMLACSDTRVKKMAMFVVAGFNLSSSLFIILLSYLFIFAAIFRIRSAEGRHKAFSTCASHLTIVTLFYGTLFCMYVRPPSEKSVEESKITAVFYTFLSPMLNPLIYSLRNTDVILAMQQMIRGKSFHKIAV | |
| CCCCCCCCCCSSSSSCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCHHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCSCCCCCCCCCHHCCHHHHHHHHHHHHHHHSSSSSCCCCCCCCCCCCSSSSSSCCCHHCCCCHHHCCCCHHHHHHHHHHHHHCCCCCCCC | |
| 999888423034786489992609999999999999999989899999962888777488887779988347201463999998714897885899999999999999999999999975413410611018812678899999999999999999999999845408899904874268188887705686277788999999999998999999999999998025676766543106488899799997433256827899988878978998822103124356440464989999999985441200369 |
| Predicted Solvent Accessibility |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MFSPNHTIVTEFILLGLTDDPVLEKILFGVFLAIYLITLAGNLCMILLIRTNSHLQTPMYFFLGHLSFVDICYSSNVTPNMLHNFLSEQKTISYAGCFTQCLLFIALVITEFYILASMALDRYVAICSPLHYSSRMSKNICVCLVTIPYMYGFLSGFSQSLLTFHLSFCGSLEINHFYCADPPLIMLACSDTRVKKMAMFVVAGFNLSSSLFIILLSYLFIFAAIFRIRSAEGRHKAFSTCASHLTIVTLFYGTLFCMYVRPPSEKSVEESKITAVFYTFLSPMLNPLIYSLRNTDVILAMQQMIRGKSFHKIAV | |
| 856513030010000000432401000013023313212333310020010003000000100200001001100000030002001542201020000001000000100000000000000000011110204003300000012012100300301011003030044120100000320002000132311011001101322331231033033101100010313632310000111021001013201100000031431334410000210331023003000020320140022004333034257 | |
| Values range from 0 (buried residue) to 9 (highly exposed residue) | |
| Predicted normalized B-factor |

| Top 10 templates used by GPCR-I-TASSER |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCCCSSSSSCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCHHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCSCCCCCCCCCHHCCHHHHHHHHHHHHHHHSSSSSCCCCCCCCCCCCSSSSSSCCCHHCCCCHHHCCCCHHHHHHHHHHHHHCCCCCCCC MFSPNHTIVTEFILLGLTDDPVLEKILFGVFLAIYLITLAGNLCMILLIRTNSHLQTPMYFFLGHLSFVDICYSSNVTPNMLHNFLSEQKTISYAGCFTQCLLFIALVITEFYILASMALDRYVAICSPLHYSSRMSKNICVCLVTIPYMYGFLSGFSQSLLTFHLSFCGSLEINHFYCADPPLIMLACSDTRVKKMAMFVVAGFNLSSSLFIILLSYLFIFAAIFRIRSAEGRHKAFSTCASHLTIVTLFYGTLFCMYVRPPSEKSVEESKITAVFYTFLSPMLNPLIYSLRNTDVILAMQQMIRGKSFHKIAV | |||||||||||||||||||||||||
| 1 | 3v2yA | 0.19 | 0.22 | 0.84 | 1.89 | Download | ------------------DKENSIKLTSVVFILICCFIILENIFVLLTIWKTKKFHRPMYYFIGNLALSDLLAGVAYTANLLLSGATTYK-LTPAQWFLREGSMFVALSASVFSLLAIAIERYITMLKN--------NFRLFLLISACWVISLILGG--------LPIMGWNCISALSSC------STVLPLYHKHYILFCTTVF--TLLLLSIVILYCRIYSLVRTRNSRSSENALLKTVIIVLSVFIACWAPLFILLLLDVGCKVKTCDILFRAEYFLVLAVTNPIIYTLTNKEMRRAFIRIMGRPL------ | |||||||||||||||||||
| 2 | 4iaqA | 0.17 | 0.22 | 0.82 | 2.11 | Download | ------------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISILYTVYSTVGAF---------------------------------------YFPTLLLIALYGRIYVEARSRIIQKYAARERKATKTLGIILGAFIVCWLPFFIISLVMPIHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK------- | |||||||||||||||||||
| 3 | 3emlA | 0.19 | 0.24 | 0.88 | 3.78 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAI-IVGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ--- | |||||||||||||||||||
| 4 | 3uonA | 0.16 | 0.23 | 0.87 | 2.56 | Download | --------------------TFEVVFIVLVAGSLSLVTIIGNILVMVSIKVNRHLQTVNNYFLFSLACADLIIGVFSMNLYTLYTVIGYWPLGPVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPVKRTTKMAGMMIAAAWVLSFILWAPAILFWQFIV--GVRTVEDGECYIQFF------S---NAAVTFGTAIAAFYLPVIIMTVLYWHISRASKSRINPSREKKVTRTILAILLAFIITWAPYNVMVLINTFCCIPNTVWTIGYWLCYINSTINPACYALCNATFKKTFKHLLM--------- | |||||||||||||||||||
| 5 | 4bvnA | 0.19 | 0.21 | 0.87 | 2.07 | Download | ------------------LSQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASVETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMMH----WWRDEDPQALKCYQDP----GCCDFVTNRAYAIASSIISFYIPLLIMIFVALRVYREAKE----MREHKALKTLGIIMGVFTLCWLPFFLVNIVNVFNRVPKWLFVAFNWLGYANSAMNPIILC-RSPDFRKAFKRLLA--------- | |||||||||||||||||||
| 6 | 3emlA | 0.21 | 0.24 | 0.88 | 4.09 | Download | ---------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCF-TFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ--- | |||||||||||||||||||
| 7 | 4bvnA | 0.19 | 0.21 | 0.88 | 2.99 | Download | ------------------LSQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASVETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMMHWWR----DEDPQALKCYQDP----GCCDFVTNRAYAIASSIISFYIPLLIMIFVALRVYREAKEQ---MREHKALKTLGIIMGVFTLCWLPFFLVNIVNNRDLVPKWLFVAFNWLGYANSAMNPIILC-RSPDFRKAFKRLLA--------- | |||||||||||||||||||
| 8 | 2z73A | 0.19 | 0.23 | 0.95 | 2.70 | Download | TWWYNPSIVVHPHWREFDQVPAVYYSLGIFIGICGIIGCGGNGIVIYLFTKTKSLQTPANMFIINLAFSDFTFSLVNGPLMTISCFLKKWIFGFAACKVYGFIGGIFGFMSIMTMAMISIDRYNVIGRPMAASKKMSHRRAFIMIIFVWLWSVLWAIGPIFGWGAYTLEGVL----------------CSRDSTTRSNILCMFILGFFGPILIIFFCYFNIVMAQAGANAEMRLAKISIVIVSQFLLSWSPYAVVALLAQFGPLEWVTPYAAQLPVMFAKASAIHNPMIYSVSHPKFREAISQTFPWVLTCCQFD | |||||||||||||||||||
| 9 | 3emlA | 0.19 | 0.24 | 0.87 | 5.82 | Download | ----------------------ISSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAI-IVGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ--- | |||||||||||||||||||
| 10 | 3emlA | 0.19 | 0.24 | 0.88 | 5.59 | Download | I--------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPL-----------LLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALC-WLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVLRQ--- | |||||||||||||||||||
| ||||||||||||||||||||||||||
| Top 5 Models predicted by GPCR-I-TASSER |
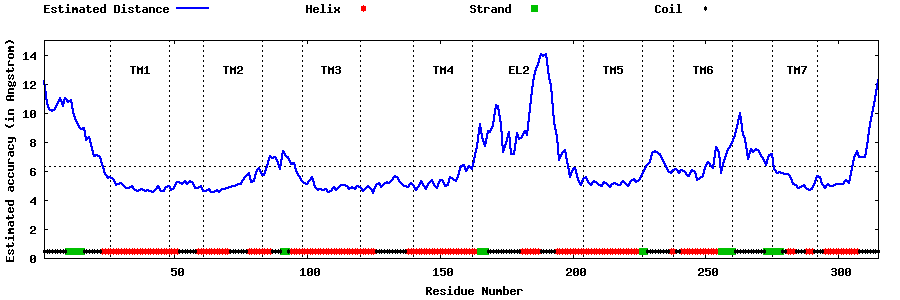
| Generated 3D models | Estimated local accuracy of models | ||
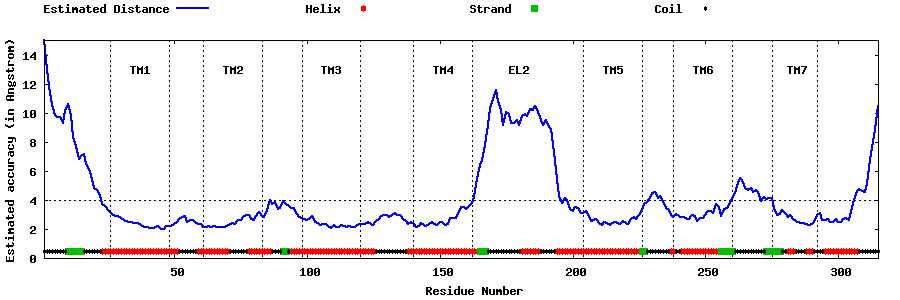 | |||
|
|
|||
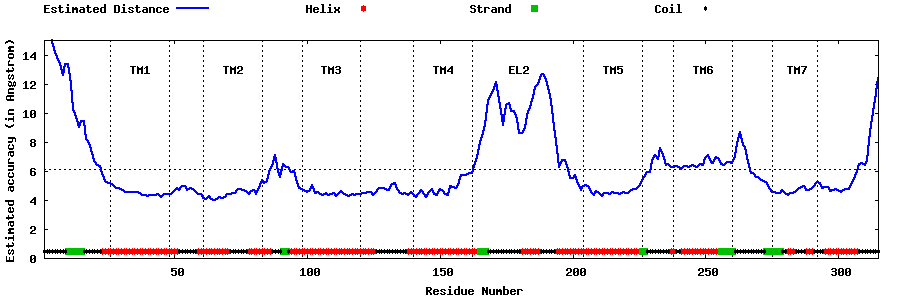 | |||
|
| |||
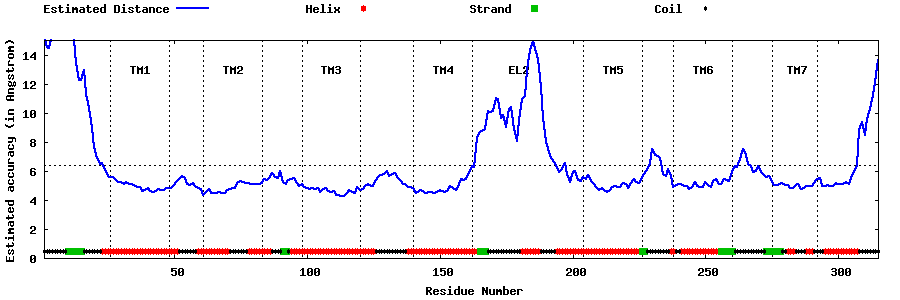 | |||
|
| |||
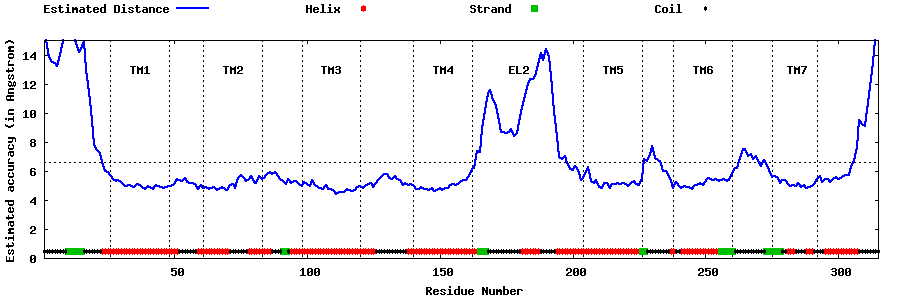 | |||
|
| |||
 | |||
|
| |||
| Please cite following articles when you use the GPCR-I-TASSER server: | |
| J Zhang, J Yang, R Jang, Y Zhang. Hybrid structure modeling of G protein-coupled receptors in the human genome, submitted (2015). |