GPCR-I-TASSER results for Q8NH54
[Click on Q8NH54_results.tar.bz2 to download the tarball file including all modeling results listed on this page]
| Submitted Sequence |
| >Q8NH54 MTTHRNDTLSTEASDFLLNCFVRSPSWQHWLSLPLSLLFLLAVGANTTLLMTIWLEASLH QPLYYLLSLLSLLDIVLCLTVIPKVLTIFWFDLRPISFPACFLQMYIMNCFLAMESCTFM VMAYDRYVAICHPLRYPSIITDHFVVKAAMFILTRNVLMTLPIPILSAQLRYCGRNVIEN CICANMSVSRLSCDDVTINHLYQFAGGWTLLGSDLILIFLSYTFILRAVLRLKAEGAVAK ALSTCGSHFMLILFFSTILLVFVLTHVAKKKVSPDVPVLLNVLHHVIPAALNPIIYGVRT QEIKQGMQRLLKKGC |
| Predicted Secondary Structure |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MTTHRNDTLSTEASDFLLNCFVRSPSWQHWLSLPLSLLFLLAVGANTTLLMTIWLEASLHQPLYYLLSLLSLLDIVLCLTVIPKVLTIFWFDLRPISFPACFLQMYIMNCFLAMESCTFMVMAYDRYVAICHPLRYPSIITDHFVVKAAMFILTRNVLMTLPIPILSAQLRYCGRNVIENCICANMSVSRLSCDDVTINHLYQFAGGWTLLGSDLILIFLSYTFILRAVLRLKAEGAVAKALSTCGSHFMLILFFSTILLVFVLTHVAKKKVSPDVPVLLNVLHHVIPAALNPIIYGVRTQEIKQGMQRLLKKGC | |
| CCCCCCCCCCCCCHHHCSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHCHCHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCCCCHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCHHHHHHHHHHHHCCCCCCCCCCCCCHHHHHHHHHHHHCCCC | |
| 988778997745355602799998668999999999999999999999999996788754238999999999999899842999999994699868888999999999999999999999998030674066645640188899999999999999999999999995089999893687332105567872478368899999999999999899999999999999807888758889855259999999999998998812503789899489999999996378563680000657999999999961589 |
| Predicted Solvent Accessibility |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MTTHRNDTLSTEASDFLLNCFVRSPSWQHWLSLPLSLLFLLAVGANTTLLMTIWLEASLHQPLYYLLSLLSLLDIVLCLTVIPKVLTIFWFDLRPISFPACFLQMYIMNCFLAMESCTFMVMAYDRYVAICHPLRYPSIITDHFVVKAAMFILTRNVLMTLPIPILSAQLRYCGRNVIENCICANMSVSRLSCDDVTINHLYQFAGGWTLLGSDLILIFLSYTFILRAVLRLKAEGAVAKALSTCGSHFMLILFFSTILLVFVLTHVAKKKVSPDVPVLLNVLHHVIPAALNPIIYGVRTQEIKQGMQRLLKKGC | |
| 744441633413222010000032342010002302321221333221000001004300200020002000201000000002000000043450304000000120131133001000000200000002101000000330000000000231101120113102002103622010000102300300021030012102320333333333203201220020003020660232001000000000221331132100001233422320100000202231133003000020330141023004453 | |
| Values range from 0 (buried residue) to 9 (highly exposed residue) | |
| Predicted normalized B-factor |

| Top 10 templates used by GPCR-I-TASSER |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCCCCCCHHHCSSCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHCHCHHHCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCCCCCHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCHHHHHHHHHHHHCCCCCCCCCCCCCHHHHHHHHHHHHCCCC MTTHRNDTLSTEASDFLLNCFVRSPSWQHWLSLPLSLLFLLAVGANTTLLMTIWLEASLHQPLYYLLSLLSLLDIVLCLTVIPKVLTIFWFDLRPISFPACFLQMYIMNCFLAMESCTFMVMAYDRYVAICHPLRYPSIITDHFVVKAAMFILTRNVLMTLPIPILSAQLRYCGRNVIENCICANMSVSRLSCDDVTINHLYQFAGGWTLLGSDLILIFLSYTFILRAVLRLKAEGAVAKALSTCGSHFMLILFFSTILLVFVLTHVAKKKVSPDVPVLLNVLHHVIPAALNPIIYGVRTQEIKQGMQRLLKKGC | |||||||||||||||||||||||||
| 1 | 3uonA | 0.16 | 0.18 | 0.85 | 2.01 | Download | ---------------------------VVFIVLVAGSLSLVTIIGNILVMVSIKVNRHLQTVNNYFLFSLACADLIIGVFSMNLYTLYTVIGYWPLGPVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPVKRTTKMAGMMIAAAWVLSFILWAPAILFWQFIVGVRTVEDGECYIQFF-----------SNAAVTFGTAIAAFYLPVIIMTVLYWHISRASKSRREK----KVTRTILAILLAFIITWAPYNVMVLINTFCAPCIPNTVWTIGYWLCYINSTINPACYALCNATFKKTFKHLL---- | |||||||||||||||||||
| 2 | 4iaqA | 0.18 | 0.22 | 0.86 | 2.00 | Download | ----------------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGRWTLGQVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISLPP-------FFWRQA--------------SECVVNTDHILYTVYSTVGAFYFPTLLLIALYGRIYVEARSRIMAARERKATKTLGIILGAFIVCWLPFFIISLVMPI-----HLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK- | |||||||||||||||||||
| 3 | 3emlA | 0.18 | 0.23 | 0.87 | 2.57 | Download | -----------------------IM-GSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIST--GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACL-----------FEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCFTFFC---PDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHV | |||||||||||||||||||
| 4 | 3uonA | 0.16 | 0.19 | 0.88 | 2.54 | Download | ------------------------TFEVVFIVLVAGSLSLVTIIGNILVMVSIKVNRHLQTVNNYFLFSLACADLIIGVFSMNLYTLYTVIGYWPLGPVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPVKRTTKMAGMMIAAAWVLSFILWAPAILFWQFIVG--VRTVEDGECYIQFF---------SNAAVTFGTAIAAFYLPVIIMTVLYWHISRASKSRINISREKKVTRTILAILLAFIITWAPYNVMVLINTFCAPCIPNTVWTIGYWLCYINSTINPACYALCNATFKKTFKHLLM--- | |||||||||||||||||||
| 5 | 4bvnA | 0.21 | 0.23 | 0.88 | 2.06 | Download | -----------------------LQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASVETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMM-H---WWRDEDPQALKCYQD----PGCCDFVTNRAYAIASSIISFYIPLLIMIFVALRVYREAKE----MREHKALKTLGIIMGVFTLCWLPFFLVNIVNVFNRDLVPKWLFVAFNWLGYANSAMNPIILC-RSPDFRKAFKRLLA--- | |||||||||||||||||||
| 6 | 3emlA | 0.17 | 0.23 | 0.87 | 2.95 | Download | -------------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIST--GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVV-----------PMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCFTFFC---PDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHV | |||||||||||||||||||
| 7 | 4bvnA | 0.22 | 0.23 | 0.87 | 2.92 | Download | -----------------------SQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASVETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMMHWWR----DEDPQALKCYQD----PGCCDFVTNRAYAIASSIISFYIPLLIMIFVALRVYREAKEQ---MREHKALKTLG---IIMGVFTLCWLPFFLVNIVNRDLVPKWLFVAFNWLGYANSAMNPIILC-RSPDFRKAFKRLLA--- | |||||||||||||||||||
| 8 | 4buoA | 0.17 | 0.20 | 0.91 | 3.18 | Download | -----NSDL----------DVNTDIYSKVLVTAIYLALFVVGTVGNSVTLFTLARKKSLQSTVDYYLGSLALSDLLILLLAMPVELYNFIWVHHPWAFAGCRGYYFLRDACTYATALNVVSLSVELYLAICHPFKAKTLMSRSRTKKFISAIWLASALLAIPMLFTMGLQNLSGDGTHPGGLVCTPIV------DTATLKVVIQVNTFMSFLFPMLVASILNTVIANKLTVMVHQRGVLVLRAVVIAFVVCWLPYHVRRLMFCYIS--DEQWTYHYFYMLTNALVYVSAAINPILYNLVSANFRQVFLSTL---- | |||||||||||||||||||
| 9 | 3emlA | 0.18 | 0.23 | 0.87 | 3.38 | Download | -----------------------I--GSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITISF----CAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPML---------WNNCGQSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCFTFFCPD---CSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHV | |||||||||||||||||||
| 10 | 3emlA | 0.17 | 0.23 | 0.87 | 4.05 | Download | IMG------------------------SSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAI--TISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVPMNYMVYFNFFACVL-----------VPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLP-LHIINCFTFF--CPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHV | |||||||||||||||||||
| ||||||||||||||||||||||||||
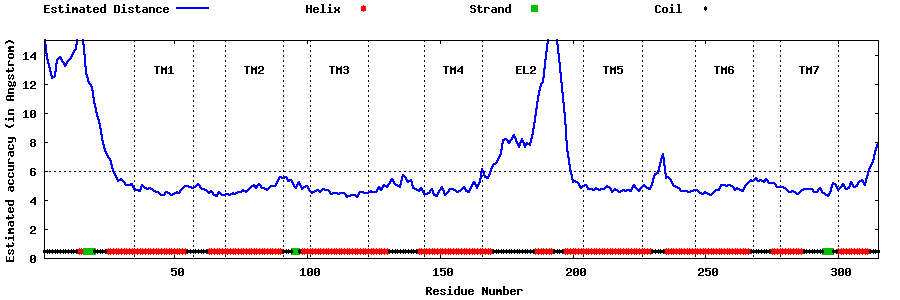
| Top 5 Models predicted by GPCR-I-TASSER |
| Generated 3D models | Estimated local accuracy of models | ||
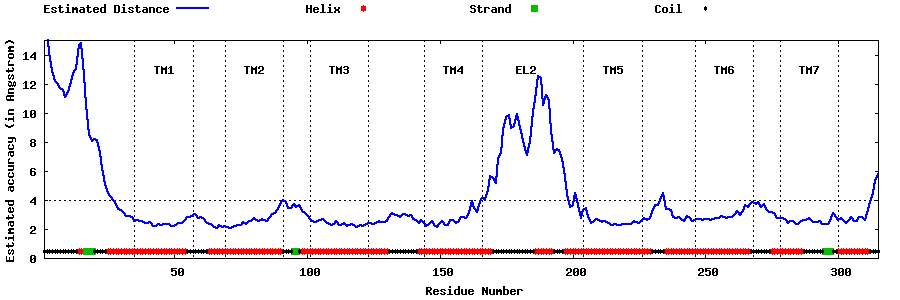 | |||
|
|
|||
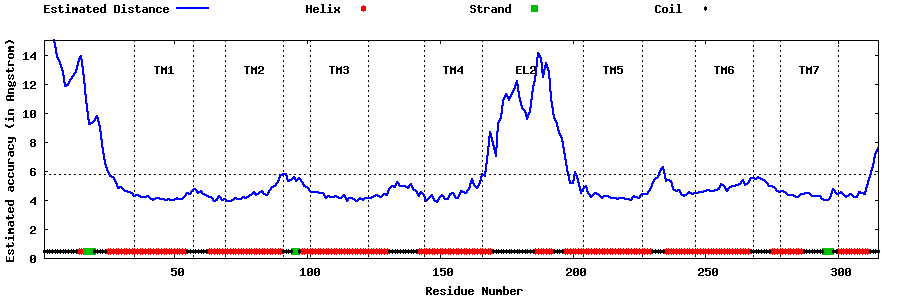 | |||
|
| |||
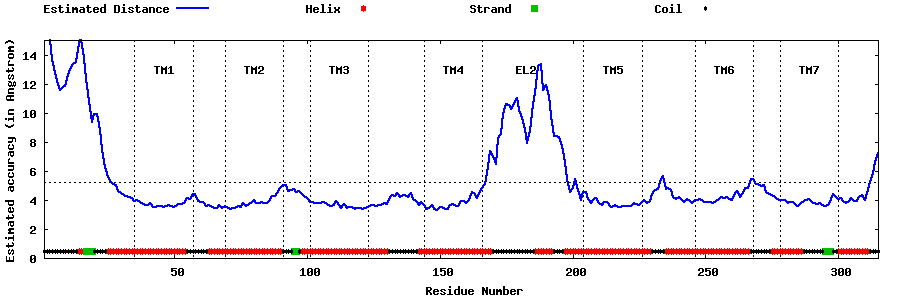 | |||
|
| |||
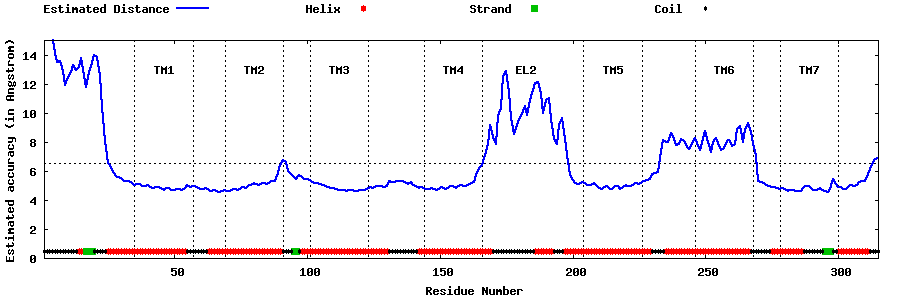 | |||
|
| |||
 | |||
|
| |||
| Please cite following articles when you use the GPCR-I-TASSER server: | |
| J Zhang, J Yang, R Jang, Y Zhang. Hybrid structure modeling of G protein-coupled receptors in the human genome, submitted (2015). |